These learning tutorials demonstrate how to perform end-to-end statistical analysis of sample data using Lisp-Stat. Sample data is provided for both the examples and the optional exercises. By completing these tutorials you will understand the tasks required for a typical statistical workflow.
This is the multi-page printable view of this section. Click here to print.
Tutorials
End to end demonstrations of statistical analysis
- 1: Basics
- 2: Data Frame
- 3: Plotting
1 - Basics
An introduction to the basics of LISP-STAT
Preface
This document is intended to be a tutorial introduction to the basics of LISP-STAT and is based on the original tutorial for XLISP-STAT written by Luke Tierney, updated for Common Lisp and the 2021 implementation of LISP-STAT.
LISP-STAT is a statistical environment built on top of the Common Lisp general purpose programming language. The first three sections contain the information you will need to do elementary statistical calculations and plotting. The fourth section introduces some additional methods for generating and modifying data. The fifth section describes some features of the user interface that may be helpful. The remaining sections deal with more advanced topics, such as interactive plots, regression models, and writing your own functions. All sections are organized around examples, and most contain some suggested exercises for the reader.
This document is not intended to be a complete manual. However, documentation for many of the commands that are available is given in the appendix. Brief help messages for these and other commands are also available through the interactive help facility described in Section 5.1 below.
Common Lisp (CL) is a dialect of the Lisp programming language, published in ANSI standard document ANSI INCITS 226-1994 (S20018) (formerly X3.226-1994 (R1999)). The Common Lisp language was developed as a standardized and improved successor of Maclisp. By the early 1980s several groups were already at work on diverse successors to MacLisp: Lisp Machine Lisp (aka ZetaLisp), Spice Lisp, NIL and S-1 Lisp. Common Lisp sought to unify, standardize, and extend the features of these MacLisp dialects. Common Lisp is not an implementation, but rather a language specification. Several implementations of the Common Lisp standard are available, including free and open-source software and proprietary products. Common Lisp is a general-purpose, multi-paradigm programming language. It supports a combination of procedural, functional, and object-oriented programming paradigms. As a dynamic programming language, it facilitates evolutionary and incremental software development, with iterative compilation into efficient run-time programs. This incremental development is often done interactively without interrupting the running application.
Using this Tutorial
The best way to learn about a new computer programming language is
usually to use it. You will get most out of this tutorial if you read
it at your computer and work through the examples yourself. To make
this tutorial easier the named data sets used in this tutorial have
been stored in the file basic.lisp in the LS:DATASETS;TUTORIALS
folder of the system. To load this file, execute:
at the command prompt (REPL). The file will be loaded and some variables will be defined for you.
Why LISP-STAT Exists
There are three primary reasons behind the decision to produce the LISP-STAT environment. The first is speed. The other major languages used for statistics and numerical analysis, R, Python and Julia are all fine languages, but with the rise of ‘big data’ and large data sets, require workarounds for processing large data sets. Furthermore, as interpreted languages, they are relatively slow when compared to Common Lisp, that has a compiler that produces native machine code.
Not only does Common Lisp provide a compiler that produces machine code, it has native threading, a rich ecosystem of code libraries, and a history of industrial deployments, including:
- Credit card authorization at AMEX (Authorizers Assistant)
- US DoD logistics (and more, that we don’t know of)
- CIA and NSA are big users based on Lisp sales
- DWave and Rigetti use lisp for programming their quantum computers
- Apple’s Siri was originally written in Lisp
- Amazon got started with Lisp & C; so did Y-combinator
- Google’s flight search engine is written in Common Lisp
- AT&T used a stripped down version of Symbolics Lisp to process CDRs in the first IP switches
Python and R are never (to my knowledge) deployed as front-line systems, but used in the back office to produce models that are executed by other applications in enterprise environments. Common Lisp eliminates that friction.
Availability
Source code for LISP-STAT is available in the Lisp-Stat github repository. The Getting Started section of the documentation contains instructions for downloading and installing the system.
Disclaimer
LISP-STAT is an experimental program. Although it is in daily use on several projects, the corporate sponsor, Symbolics Pte Ltd, takes no responsibility for losses or damages resulting directly or indirectly from the use of this program.
LISP-STAT is an evolving system. Over time new features will be introduced, and existing features that do not work may be changed. Every effort will be made to keep LISP-STAT consistent with the information in this tutorial, but if this is not possible the reference documentation should give accurate information about the current use of a command.
Starting and Finishing
Once you have obtained the source code or pre-built image, you can load Lisp-Stat using QuickLisp. If you do not have quicklisp, stop here and get it. It is the de-facto package manager for Common Lisp and you will need it. This is what you will see if loading using the Slime IDE:
You may see more or less output, depending on whether dependent packages have been compiled before. If this is your first time running anything in this implementation of Common Lisp, you will probably see output related to the compilation of every module in the system. This could take a while, but only has to be done once.
Once completed, to use the functions provided, you need to make the LISP-STAT package the current package, like this:
The final LS-USER> in the window is the Slime prompt. Notice how it
changes when you executed (in-package). In Slime, the prompt always
indicates the current package, *package*. Any characters you type
while the prompt is active will be added to the line after the final
prompt. When you press return, LISP-STAT will try to interpret what
you have typed and will print a response. For example, if you type a
1 and press return then LISP-STAT will respond by simply printing a
1 on the following line and then give you a new prompt:
If you type an expression like (+ 1 2), then LISP-STAT will
print the result of evaluating the expression and give you a new prompt:
As you have probably guessed, this expression means that the numbers 1
and 2 are to be added together. The next section will give more
details on how LISP-STAT expressions work. In this tutorial I will
sometimes show interactions with the program as I have done here: The
LS-USER> prompt will appear before lines you should type.
LISP-STAT will supply this prompt when it is ready; you should not
type it yourself. In later sections I will omit the new prompt
following the result in order to save space.
Now that you have seen how to start up LISP-STAT it is a good idea to make sure you know how to get out. The exact command to exit depends on the Common Lisp implementation you use. For SBCL, you can type the expression
In other implementations, the command is quit. One of these methods
should cause the program to exit and return you to the IDE. In Slime,
you can use the , short-cut and then type sayoonara.
The Basics
Before we can start to use LISP-STAT for statistical work we need to learn a little about the kind of data LISP-STAT uses and about how the LISP-STAT listener and evaluator work.
Data
LISP-STAT works with two kinds of data: simple data and compound data. Simple data are numbers
1 ; an integer
-3.14 ; a floating point number
#C(0 1) ; a complex number (the imaginary unit)
logical values
T ; true
nil ; false
strings (always enclosed in double quotes)
"This is a string 1 2 3 4"
and symbols (used for naming things; see the following section)
x
x12
12x
this-is-a-symbol
Compound data are lists
(this is a list with 7 elements)
(+ 1 2 3)
(sqrt 2)
or vectors
#(this is a vector with 7 elements)
#(1 2 3)
Higher dimensional arrays are another form of compound data; they will be discussed below in Section 9, “Arrays”.
All the examples given above can be typed directly into the command window as they are shown here. The next subsection describes what LISP-STAT will do with these expressions.
The Listener and the Evaluator
A session with LISP-STAT basically consists of a conversation between you and the listener. The listener is the window into which you type your commands. When it is ready to receive a command it gives you a prompt. At the prompt you can type in an expression. You can use the mouse or the backspace key to correct any mistakes you make while typing in your expression. When the expression is complete and you type a return the listener passes the expression on to the evaluator. The evaluator evaluates the expression and returns the result to the listener for printing.1 The evaluator is the heart of the system.
The basic rule to remember in trying to understand how the evaluator works is that everything is evaluated. Numbers and strings evaluate to themselves:
LS-USER> 1
1
LS-USER> "Hello"
"Hello"
LS-USER>
Lists are more complicated. Suppose you type the list (+ 1 2 3)
at the listener. This list has four elements: the symbol +
followed by the numbers 1, 2 and 3. Here is what happens:
> (+ 1 2 3)
6
>
This list is evaluated as a function application. The first element
is a symbol representing a function, in this case the symbol +
representing the addition function. The remaining elements are the
arguments. Thus the list in the example above is interpreted to mean
“Apply the function + to the numbers 1, 2 and 3”.
Actually, the arguments to a function are always evaluated before the function is applied. In the previous example the arguments are all numbers and thus evaluate to themselves. On the other hand, consider
LS-USER> (+ (* 2 3) 4)
10
LS-USER>
The evaluator has to evaluate the first argument to the function
+ before it can apply the function.
Occasionally you may want to tell the evaluator not to evaluate
something. For example, suppose we wanted to get the evaluator to simply
return the list (+ 1 2) back to us, instead of evaluating it. To
do this we need to quote our list:
LS-USER> (quote (+ 1 2))
(+ 1 2)
LS-USER>
quote is not a function. It does not obey the rules of function
evaluation described above: Its argument is not evaluated. quote is
called a special form – special because it has special rules for
the treatment of its arguments. There are a few other special forms
that we will need; I will introduce them as they are needed. Together
with the basic evaluation rules described here these special forms
make up the basics of the Lisp language. The special form quote is
used so often that a shorthand notation has been developed, a single
quote before the expression you want to quote:
LS-USER> '(+ 1 2) ; single quote shorthand
This is equivalent to (quote (+ 1 2)). Note that there is no
matching quote following the expression.
By the way, the semicolon ; is the Lisp comment character.
Anything you type after a semicolon up to the next time you press
return is ignored by the evaluator.
Exercises
For each of the following expressions try to predict what the evaluator will return. Then type them in, see what happens and try to explain any differences.
-
(+ 3 5 6) -
(+ (- 1 2) 3) -
’(+ 3 5 6) -
’( + (- 1 2) 3) -
(+ (- (* 2 3) (/ 6 2)) 7) -
’x
Remember, to quit from LISP-STAT type (exit), quit or use the
IDE’s exit mechanism.
Elementary Statistical Operations
This section introduces some of the basic graphical and numerical statistical operations that are available in LISP-STAT.
First Steps
Statistical data usually consists of groups of numbers. Devore and Peck [@DevorePeck Exercise 2.11] describe an experiment in which 22 consumers reported the number of times they had purchased a product during the previous 48 week period. The results are given as a table:
0 2 5 0 3 1 8 0 3 1 1
9 2 4 0 2 9 3 0 1 9 8
To examine this data in LISP-STAT we represent it as a list of numbers
using the list function:
Note
The text boxes above have a ‘copy’ button if you hover on them. For some examples, I will give the commands alone in the text box so that you can copy & paste the code into the REPLNote that the numbers are separated by white space (spaces, tabs or even returns), not commas.
The mean function can be used to compute the average of a list of
numbers. We can combine it with the list function to find the
average number of purchases for our sample:
The median of these numbers can be computed as
It is of course a nuisance to have to type in the list of 22 numbers
every time we want to compute a statistic for the sample. To avoid
having to do this I will give this list a name using the def
special form 2:
Now the symbol purchases has a value associated with it: Its
value is our list of 22 numbers. If you give the symbol purchases
to the evaluator then it will find the value of this symbol and return
that value:
LS-USER> purchases
(0 2 5 0 3 1 8 0 3 1 1 9 2 4 0 2 9 3 0 1 9 8)
Note
Common Lisp provides two functions to define variablesdefparameter and defvar. Variables defined with
defparameter can be modified without a warning. If you attempt to
modify a variable defined with defvar a warning will be issued and
you will have to confirm the change.
We can now easily compute various numerical descriptive statistics for this data set:
LS-USER> (mean purchases)
3.227273
LS-USER> (median purchases)
2
LS-USER> (sd purchases)
3.2795
LS-USER> (interquartile-range purchases)
4
LISP-STAT also supports elementwise arithmetic operations on vectors
of numbers. Technically, overriding, or ‘shadowing’ any of the Common
Lisp functions is undefined. This is usually an euphuism for
‘something really bad will happen’, so the vector functions are
located in the package elmt and prefixed by e to distinguish them
from the Common Lisp variants, e.g. e+ for addition, e* for
multiplication, etc. Presently these functions work only on vectors,
so we’ll define a new purchases variable as a vector type:
The # symbol tells the listener to interpret the list as a vector,
much like the ' signals a list.
Warning
Lists are fine for small data-sets, but can rapidly cause memory exhaustion when they are large. Get into the habit of using vectors with Lisp-StatNow we can add 1 to each of the purchases:
LS-USER> (e+ 1 purchases-2)
(1 3 6 1 4 2 9 1 4 2 2 10 3 5 1 3 10 4 1 2 10 9)
and after adding 1 we can compute the natural logarithms of the results:
LS-USER> (elog (e+ 1 purchases-2))
(0 1.098612 1.791759 0 1.386294 0.6931472 2.197225 0 1.386294 0.6931472
0.6931472 2.302585 1.098612 1.609438 0 1.098612 2.302585 1.386294 0
0.6931472 2.302585 2.197225)
Note
Using thee prefix for mathematical
operators is a temporary situation. We know how to merge vectorized
mathematics into the base Common Lisp, but since we have a functioning
system, this work is lower priority. Volunteers to take this on are
welcome.
Exercises
For each of the following expressions try to predict what the evaluator will return. Then type them in, see what happens and try to explain any differences.
-
(mean (list 1 2 3)) -
(e+ #(1 2 3) 4) -
(e* #(1 2 3) #(4 5 6)) -
(e+ #(1 2 3) #(4 5 7))
Summary Statistics
Devore and Peck [@DevorePeck page 54, Table 10] give precipitation
levels recorded during the month of March in the Minneapolis - St. Paul
area over a 30 year period. Let’s enter these data into LISP-STAT with
the name precipitation:
In typing the expression above I have inserted return and tab a few times in order to make the typed expression easier to read. The tab key indents the next line to a reasonable point to make the expression more readable.
Here are some numerical summaries:
LS-USER> (mean precipitation)
1.685
LS-USER> (median precipitation)
1.47
LS-USER> (standard-deviation precipitation)
1.0157
LS-USER> (interquartile-range precipitation)
1.145
The distribution of this data set is somewhat skewed to the right. Notice the separation between the mean and the median. You might want to try a few simple transformations to see if you can symmetrize the data. Square root and log transformations can be computed using the expressions
and
You should look at plots of the data to see if these transformations do indeed lead to a more symmetric shape. The means and medians of the transformed data are:
Generating and Modifying Data
This section briefly summarizes some techniques for generating random and systematic data.
Generating Random Data
The state of the internal random number generator can be “randomly”
reseeded, and the current value of the generator state can be saved. The
mechanism used is the standard Common Lisp mechanism. The current random
state is held in the variable *random-state*. The function
make-random-state can be used to set and save the state. It takes
an optional argument. If the argument is NIL or omitted
make-random-state returns a copy of the current value of
*random-state*. If the argument is a state object, a copy of it is
returned. If the argument is t a new, “randomly” initialized
state object is produced and returned. 3
Forming Subsets and Deleting Cases
The select function allows you to select a single element or a
group of elements from a list or vector. For example, if we define
x by
then (select x i) will return the ith element of x.
Common Lisp, like the language C, but in contrast to FORTRAN, numbers
elements of list and vectors starting at zero. Thus the indices for
the elements of x are 0, 1, 2, 3, 4, 5, 6, 7 . So
LS-USER> (select x 0)
3
LS-USER> (select x 2)
5
To get a group of elements at once we can use a list of indices instead of a single index:
LS-USER> (select x (list 0 2))
(3 5)
If you want to select all elements of x except element 2 you can
use the expression
as the second argument to the function select:
Combining Lists & Vectors
At times you may want to combine several short lists or vectors into a
single longer one. This can be done using the append function. For
example, if you have three variables x, y and z constructed by
the expressions
then the expression
will return the list
(1 2 3 4 5 6 7 8).
For vectors, we use the more general function concatenate, which
operates on sequences, that is objects of either list or vector:
Notice that we had to indicate the return type, using the 'vector
argument to concatenate. We could also have said 'list to have it
return a list, and it would have coerced the arguments to the correct
type.
Modifying Data
So far when I have asked you to type in a list of numbers I have been
assuming that you will type the list correctly. If you made an error
you had to retype the entire def expression. Since you can use
cut & paste this is really not too serious. However it would be
nice to be able to replace the values in a list after you have typed
it in. The setf special form is used for this. Suppose you would
like to change the 12 in the list x used in the Section
4.3 to 11. The expression
will make this replacement:
The general form of setf is
where form is the expression you would use to select a single
element or a group of elements from x and value is the
value you would like that element to have, or the list of the values for
the elements in the group. Thus the expression
changes the values of elements 0 and 2 to 15 and 16:
LS-USER> (setf (select x (list 0 2)) (list 15 16))
(15 16)
LS-USER> x
(15 7 16 9 11 3 14 2)
Caution
Lisp symbols are merely labels for
different items. When you assign a name to an item with the defvar or defparameter
commands you are not producing a new item. Thus
(defparameter x (list 1 2 3 4))
(defparameter y x)
means that x and y are two different names for the same
thing.
As a result, if we change an element of (the item referred to by) x
with setf then we are also changing the element of (the item
referred to by) y, since both x and y refer to the same item. If
you want to make a copy of x and store it in y before you make
changes to x then you must do so explicitly using, say, the
copy-list function. The
expression
will make a copy of x and set the value of y to that copy.
Now x and y refer to different items and changes to
x will not affect y.
Useful Shortcuts
This section describes some additional features of LISP-STAT that you may find useful.
Getting Help
On line help is available for many of the functions in LISP-STAT 4.
As an example, here is how you would get help for the function
iota:
LS-USER> (documentation 'iota 'function)
"Return a list of n numbers, starting from START (with numeric contagion
from STEP applied), each consecutive number being the sum of the previous one
and STEP. START defaults to 0 and STEP to 1.
Examples:
(iota 4) => (0 1 2 3)
(iota 3 :start 1 :step 1.0) => (1.0 2.0 3.0)
(iota 3 :start -1 :step -1/2) => (-1 -3/2 -2)
"
Note the quote in front of iota. documentation is itself a
function, and its argument is the symbol representing the function
iota. To make sure documentation receives the symbol, not the
value of the symbol, you need to quote the symbol.
Another useful function is describe that, depending on the Lisp
implementation, will return documentation and additional information
about the object:
LS-USER> (describe 'iota)
ALEXANDRIA:IOTA
[symbol]
IOTA names a compiled function:
Lambda-list: (ALEXANDRIA::N &KEY (ALEXANDRIA::START 0) (STEP 1))
Derived type: (FUNCTION
(UNSIGNED-BYTE &KEY (:START NUMBER) (:STEP NUMBER))
(VALUES T &OPTIONAL))
Documentation:
Return a list of n numbers, starting from START (with numeric contagion
from STEP applied), each consecutive number being the sum of the previous one
and STEP. START defaults to 0 and STEP to 1.
Examples:
(iota 4) => (0 1 2 3)
(iota 3 :start 1 :step 1.0) => (1.0 2.0 3.0)
(iota 3 :start -1 :step -1/2) => (-1 -3/2 -2)
Inline proclamation: INLINE (inline expansion available)
Source file: s:/src/third-party/alexandria/alexandria-1/numbers.lisp
Note
Generally describe is better to use than documentation. The ANSI Common Lisp spec
has this to say about documentation:
“Documentation strings are made available for debugging purposes. Conforming programs are permitted to use documentation strings when they are present, but should not depend for their correct behavior on the presence of those documentation strings. An implementation is permitted to discard documentation strings at any time for implementation-defined reasons.”
If you are not sure about the name of a function you may still be able to get some help. Suppose you want to find out about functions related to the normal distribution. Most such functions will have “norm” as part of their name. The expression
(apropos 'norm)
will print the help information for all symbols whose names contain the string “norm”:
ALEXANDRIA::NORMALIZE
ALEXANDRIA::NORMALIZE-AUXILARY
ALEXANDRIA::NORMALIZE-KEYWORD
ALEXANDRIA::NORMALIZE-OPTIONAL
ASDF/PARSE-DEFSYSTEM::NORMALIZE-VERSION (fbound)
ASDF/FORCING:NORMALIZE-FORCED-NOT-SYSTEMS (fbound)
ASDF/FORCING:NORMALIZE-FORCED-SYSTEMS (fbound)
ASDF/SESSION::NORMALIZED-NAMESTRING
ASDF/SESSION:NORMALIZE-NAMESTRING (fbound)
CL-INTERPOL::NORMAL-NAME-CHAR-P (fbound)
CL-PPCRE::NORMALIZE-VAR-LIST (fbound)
DISTRIBUTIONS::+NORMAL-LOG-PDF-CONSTANT+ (bound, DOUBLE-FLOAT)
DISTRIBUTIONS::CDF-NORMAL% (fbound)
DISTRIBUTIONS::COPY-LEFT-TRUNCATED-NORMAL (fbound)
DISTRIBUTIONS::COPY-R-LOG-NORMAL (fbound)
DISTRIBUTIONS::COPY-R-NORMAL (fbound)
DISTRIBUTIONS::DRAW-LEFT-TRUNCATED-STANDARD-NORMAL (fbound)
DISTRIBUTIONS::LEFT-TRUNCATED-NORMAL (fbound)
DISTRIBUTIONS::LEFT-TRUNCATED-NORMAL-ALPHA (fbound)
DISTRIBUTIONS::LEFT-TRUNCATED-NORMAL-LEFT (fbound)
DISTRIBUTIONS::LEFT-TRUNCATED-NORMAL-LEFT-STANDARDIZED (fbound)
DISTRIBUTIONS::LEFT-TRUNCATED-NORMAL-M0 (fbound)
DISTRIBUTIONS::LEFT-TRUNCATED-NORMAL-MU (fbound)
DISTRIBUTIONS::LEFT-TRUNCATED-NORMAL-P (fbound)
DISTRIBUTIONS::LEFT-TRUNCATED-NORMAL-SIGMA (fbound)
DISTRIBUTIONS::MAKE-LEFT-TRUNCATED-NORMAL (fbound)
DISTRIBUTIONS::MAKE-R-LOG-NORMAL (fbound)
DISTRIBUTIONS::MAKE-R-NORMAL (fbound)
DISTRIBUTIONS::QUANTILE-NORMAL% (fbound)
DISTRIBUTIONS::R-LOG-NORMAL-LOG-MEAN (fbound)
...
Let me briefly explain the notation used in the information printed by
describe regarding the arguments a function expects 5. This is
called the lambda-list. Most functions expect a fixed set of
arguments, described in the help message by a line like Args: (x y z) or Lambda-list: (x y z)
Some functions can take one or more optional arguments. The arguments for such a function might be listed as
Args: (x &optional y (z t))
or
Lambda-list: (x &optional y (z t))
This means that x is required and y and z are
optional. If the function is named f, it can be called as
(f x-val), (f x-val y-val) or
(f x-val y-val z-val). The list (z t) means that if
z is not supplied its default value is T. No explicit
default value is specified for y; its default value is therefore
NIL. The arguments must be supplied in the order in which they
are listed. Thus if you want to give the argument z you must also
give a value for y.
Another form of optional argument is the keyword argument. The
iota function for example takes arguments
Args: (N &key (START 0) (STEP 1))
The n argument is required, the START argument is an optional
keyword argument. The default START is 0, and the default STEP
is 1. If you want to create a sequence eight numbers, with a step of
two) use the expression
(iota 8 :step 2)
Thus to give a value for a keyword argument you give the keyword 6 for the argument, a symbol consisting of a colon followed by the argument name, and then the value for the argument. If a function can take several keyword arguments then these may be specified in any order, following the required and optional arguments.
Finally, some functions can take an arbitrary number of arguments. This is denoted by a line like
Args: (x &rest args)
The argument x is required, and zero or more additional arguments
can be supplied.
In addition to providing information about functions describe also
gives information about data types and certain variables. For example,
LS-USER> (describe 'complex)
COMMON-LISP:COMPLEX
[symbol]
COMPLEX names a compiled function:
Lambda-list: (REALPART &OPTIONAL (IMAGPART 0))
Declared type: (FUNCTION (REAL &OPTIONAL REAL)
(VALUES NUMBER &OPTIONAL))
Derived type: (FUNCTION (T &OPTIONAL T)
(VALUES
(OR RATIONAL (COMPLEX SINGLE-FLOAT)
(COMPLEX DOUBLE-FLOAT) (COMPLEX RATIONAL))
&OPTIONAL))
Documentation:
Return a complex number with the specified real and imaginary components.
Known attributes: foldable, flushable, unsafely-flushable, movable
Source file: SYS:SRC;CODE;NUMBERS.LISP
COMPLEX names the built-in-class #<BUILT-IN-CLASS COMMON-LISP:COMPLEX>:
Class precedence-list: COMPLEX, NUMBER, T
Direct superclasses: NUMBER
Direct subclasses: SB-KERNEL:COMPLEX-SINGLE-FLOAT,
SB-KERNEL:COMPLEX-DOUBLE-FLOAT
Sealed.
No direct slots.
COMPLEX names a primitive type-specifier:
Lambda-list: (&OPTIONAL (SB-KERNEL::TYPESPEC '*))
shows the function, type and class documentation for complex, and
LS-USER> (documentation 'pi 'variable)
PI [variable-doc]
The floating-point number that is approximately equal to the ratio of the
circumference of a circle to its diameter.
shows the variable documentation for pi7.
Listing and Undefining Variables
After you have been working for a while you may want to find out what
variables you have defined (using def). The function
variables will produce a listing:
LS-USER> (variables)
CO
HC
RURAL
URBAN
PRECIPITATION
PURCHASES
NIL
LS-USER>
If you are working with very large variables you may occasionally want
to free up some space by getting rid of some variables you no longer
need. You can do this using the undef-var function:
LS-USER> (undef-var 'co)
CO
LS-USER> (variables)
HC
RURAL
URBAN
PRECIPITATION
PURCHASES
NIL
LS-USER>
More on the Listener
Common Lisp provides a simple command history mechanism. The symbols
-, ``, *, **, +, ++, and +++ are used for this purpose. The
top level reader binds these symbols as follows:
`-` the current input expression
`+` the last expression read
`++` the previous value of `+`
`+++` the previous value of `++`
`` the result of the last evaluation
`*` the previous value of ``
`**` the previous value of `*`
The variables ``, * and ** are probably most useful.
For example, if you read a data-frame but forget to assign the resulting object to a variable:
you can recover it using one of the history variables:
The symbol MTCARS now has the data-frame object as its value.
Like most interactive systems, Common Lisp needs a system for dynamically managing memory. The system used depends on the implementation. The most common way (SBCL, CCL) is to grab memory out of a fixed bin until the bin is exhausted. At that point the system pauses to reclaim memory that is no longer being used. This process, called garbage collection, will occasionally cause the system to pause if you are using large amounts of memory.
Loading Files
The data for the examples and exercises in this tutorial, when not
loaded from the network, have been stored on files with names ending
in .lisp. In the LISP-STAT system directory they can be found in the
folder Datasets. Any variables you save (see the next subsection for
details) will also be saved in files of this form. The data in these
files can be read into LISP-STAT with the load function. To load a
file named randu.lisp type the expression
or just
If you give load a name that does not end in .lisp then
load will add this suffix.
Saving Your Work
Save a Session
If you want to record a session with LISP-STAT you can do so using the
dribble function. The expression
starts a recording. All expressions typed by you and all results
printed by LISP-STAT will be entered into the file named myfile.
The expression
stops the recording. Note that (dribble "myfile") starts a new
file by the name myfile. If you already have a file by that name
its contents will be lost. Thus you can’t use dribble to toggle on and
off recording to a single file.
dribble only records text that is typed, not plots. However, you
can use the buttons displayed on a plot to save in SVG or PNG format.
The original HTML plots are saved in your operating system’s TEMP
directory and can be viewed again until the directory is cleared
during a system reboot.
Saving Variables
Variables you define in LISP-STAT only exist for the duration of the
current session. If you quit from LISP-STAT your data will be lost.
To preserve your data you can use the savevar function. This
function allows you to save one a variable into a file. Again
a new file is created and any existing file by the same name is
destroyed. To save the variable precipitation in a file called
precipitation type
Do not add the .lisp suffix yourself; save will supply
it. To save the two variables precipitation and purchases
in the file examples.lisp type 8.
The files precipitation.lisp and examples.lisp now contain a set
of expression that, when read in with the load command, will
recreate the variables precipitation and purchases. You can look
at these files with an editor like the Emacs editor and you can
prepare files with your own data by following these examples.
Reading Data Files
The data files we have used so far in this tutorial have contained
Common Lisp expressions. LISP-STAT also provides functions for
reading raw data files. The most commonly used is read-csv.
where stream is a Common Lisp stream with the data. Streams can be
obtained from files, strings or a network and are in comma separated
value (CSV) format. The parser supports delimiters other than comma.
The character delimited reader should be adequate for most purposes. If you have to read a file that is not in a character delimited format you can use the raw file handling functions of Common Lisp.
User Initialization File
Each Common Lisp implementation provides a way to execute initialization code upon start-up. You can use this file to load any data sets you would like to have available or to define functions of your own.
LISP-STAT also has an initialization file, ls-init.lisp, in your
home directory. Typically you will use the lisp implementation
initialization file for global level initialization, and
ls-init.lisp for data related customizations. See the section
Initialization
file in the
manual for more information.
Defining Functions & Methods
This section gives a brief introduction to programming LISP-STAT. The most basic programming operation is to define a new function. Closely related is the idea of defining a new method for an object. 9
Defining Functions
You can use the Common Lisp language to define functions of your
own. Many of the functions you have been using so far are written in
this language. The special form used for defining functions is called
defun. The simplest form of the defun syntax is
(defun fun args expression)
where fun is the symbol you want to use as the function name, args
is the list of the symbols you want to use as arguments, and
expression is the body of the function. Suppose for example that
you want to define a function to delete a case from a list. This
function should take as its arguments the list and the index of the
case you want to delete. The body of the function can be based on
either of the two approaches described in Section
4.3 above. Here is one approach:
I have used the function length in this definition to determine
the length of the argument x. Note that none of the arguments to
defun are quoted: defun is a special form that does not
evaluate its arguments.
Unless the functions you define are very simple you will probably want
to define them in a file and load the file into LISP-STAT with the
load command. You can put the functions in the implementation’s initialization
file or include in the initialization file a load
command that will load another file. The version of Common Lisp for the
Macintosh, CCL, includes a simple editor that can be used from within
LISP-STAT.
Matrices and Arrays
LISP-STAT includes support for multidimensional arrays. In addition to the standard Common Lisp array functions, LISP-STAT also includes a system called array-operations.
An array is printed using the standard Common Lisp format. For example, a 2 by 3 matrix with rows (1 2 3) and (4 5 6) is printed as
#2A((1 2 3)(4 5 6))
The prefix #2A indicates that this is a two-dimensional array. This
form is not particularly readable, but it has the advantage that it can
be pasted into expressions and will be read as an array by the LISP
reader.10 For matrices you can use the function print-matrix
to get a slightly more readable representation:
LS-USER> (print-matrix '#2a((1 2 3)(4 5 6)) *standard-output*)
1 2 3
4 5 6
NIL
The select function can be used to extract elements or sub-arrays
from an array. If A is a two dimensional array then the
expression
(select a 0 1)
will return element 1 of row 0 of A. The expression
(select a (list 0 1) (list 0 1))
returns the upper left hand corner of A.
References
Bates, D. M. and Watts, D. G., (1988), Nonlinear Regression Analysis and its Applications, New York: Wiley.
Becker, Richard A., and Chambers, John M., (1984), S: An Interactive Environment for Data Analysis and Graphics, Belmont, Ca: Wadsworth.
Becker, Richard A., Chambers, John M., and Wilks, Allan R., (1988), The New S Language: A Programming Environment for Data Analysis and Graphics, Pacific Grove, Ca: Wadsworth.
Becker, Richard A., and William S. Cleveland, (1987), “Brushing scatterplots,” Technometrics, vol. 29, pp. 127-142.
Betz, David, (1985) “An XLISP Tutorial,” BYTE, pp 221.
Betz, David, (1988), “XLISP: An experimental object-oriented programming language,” Reference manual for XLISP Version 2.0.
Chaloner, Kathryn, and Brant, Rollin, (1988) “A Bayesian approach to outlier detection and residual analysis,” Biometrika, vol. 75, pp. 651-660.
Cleveland, W. S. and McGill, M. E., (1988) Dynamic Graphics for Statistics, Belmont, Ca.: Wadsworth.
Cox, D. R. and Snell, E. J., (1981) Applied Statistics: Principles and Examples, London: Chapman and Hall.
Dennis, J. E. and Schnabel, R. B., (1983), Numerical Methods for Unconstrained Optimization and Nonlinear Equations, Englewood Cliffs, N.J.: Prentice-Hall.
Devore, J. and Peck, R., (1986), Statistics, the Exploration and Analysis of Data, St. Paul, Mn: West Publishing Co.
McDonald, J. A., (1982), “Interactive Graphics for Data Analysis,” unpublished Ph. D. thesis, Department of Statistics, Stanford University.
Oehlert, Gary W., (1987), “MacAnova User’s Guide,” Technical Report 493, School of Statistics, University of Minnesota.
Press, Flannery, Teukolsky and Vetterling, (1988), Numerical Recipes in C, Cambridge: Cambridge University Press.
Steele, Guy L., (1984), Common Lisp: The Language, Bedford, MA: Digital Press.
Stuetzle, W., (1987), “Plot windows,” J. Amer. Statist. Assoc., vol. 82, pp. 466 - 475.
Tierney, Luke, (1990) LISP-STAT: Statistical Computing and Dynamic Graphics in Lisp. Forthcoming.
Tierney, L. and J. B. Kadane, (1986), “Accurate approximations for posterior moments and marginal densities,” J. Amer. Statist. Assoc., vol. 81, pp. 82-86.
Tierney, Luke, Robert E. Kass, and Joseph B. Kadane, (1989), “Fully exponential Laplace approximations to expectations and variances of nonpositive functions,” J. Amer. Statist. Assoc., to appear.
Tierney, L., Kass, R. E., and Kadane, J. B., (1989), “Approximate marginal densities for nonlinear functions,” Biometrika, to appear.
Weisberg, Sanford, (1982), “MULTREG Users Manual,” Technical Report 298, School of Statistics, University of Minnesota.
Winston, Patrick H. and Berthold K. P. Horn, (1988), LISP, 3rd Ed., New York: Addison-Wesley.
Appendix A: LISP-STAT Interface to the Operating System
A.1 Running System Commands from LISP-STAT
The run-program function can be used to run UNIX commands from within
LISP-STAT. This function takes a shell command string as its argument
and returns the shell exit code for the command. For example, you can
print the date using the UNIX date command:
LS-USER> (uiop:run-program "date" :output *standard-output*)
Wed Jul 19 11:06:53 CDT 1989
0
The return value is 0, indicating successful completion of the UNIX command.
-
It is possible to make a finer distinction. The reader takes a string of characters from the listener and converts it into an expression. The evaluator evaluates the expression and the printer converts the result into another string of characters for the listener to print. For simplicity I will use evaluator to describe the combination of these functions. ↩︎
-
defacts like a special form, rather than a function, since its first argument is not evaluated (otherwise you would have to quote the symbol). Technicallydefis a macro, not a special form, but I will not worry about the distinction in this tutorial.defis closely related to the standard Lisp special formssetfandsetq. The advantage of usingdefis that it adds your variable name to a list ofdef‘ed variables that you can retrieve using the functionvariables. If you usesetforsetqthere is no easy way to find variables you have defined, as opposed to ones that are predefined.defalways affects top level symbol bindings, not local bindings. It cannot be used in function definitions to change local bindings. ↩︎ -
The generator used is Marsaglia’s portable generator from the Core Math Libraries distributed by the National Bureau of Standards. A state object is a vector containing the state information of the generator. “Random” reseeding occurs off the system clock. ↩︎
-
Help is available both in the REPL, and online at https://lisp-stat.dev/ ↩︎
-
The notation used corresponds to the specification of the argument lists in Lisp function definitions. See Section 8{reference-type=“ref” reference=“Fundefs”} for more information on defining functions. ↩︎
-
Note that the keyword
:titlehas not been quoted. Keyword symbols, symbols starting with a colon, are somewhat special. When a keyword symbol is created its value is set to itself. Thus a keyword symbol effectively evaluates to itself and does not need to be quoted. ↩︎ -
Actually
pirepresents a constant, produced withdefconst. Its value cannot be changed by simple assignment. ↩︎ -
I have used a quoted list
’(purchases precipitation)in this expression to pass the list of symbols to thesavevarfunction. A longer alternative would be the expression(list ’purchases ’precipitation).↩︎ -
The discussion in this section only scratches the surface of what you can do with functions in the XLISP language. To see more examples you can look at the files that are loaded when XLISP-STAT starts up. For more information on options of function definition, macros, etc. see the XLISP documentation and the books on Lisp mentioned in the references. ↩︎
-
You should quote an array if you type it in using this form, as the value of an array is not defined. ↩︎
2 - Data Frame
A Data Frame Primer
Load data frame
Load data
We will use one of the example data sets from R, mtcars, for these examples. First, switch into the Lisp-Stat package:
Now load the data:
Examine data
Lisp-Stat’s printing system is integrated with the Common Lisp Pretty
Printing
facility. To control aspects of printing, you can use the built in
lisp pretty printing configuration system. By default Lisp-Stat sets
*print-pretty* to nil.
Basic information
Type the name of the data frame at the REPL to get a simple one-line summary.
Printing data
By default, the head function will print the first 6 rows:
and tail the last 6 rows:
print-data can be used to print the whole data frame:
The two dots “..” at the end indicate that output has been truncated.
Lisp-Stat sets the default for pretty printer *print-lines* to 25
rows and output more than this is truncated. If you’d like to print
all rows, set this value to nil, (setf *print-lines* nil)
Notice the column named X1. This is the name given to the column by
the data reading function. Note the warning that was issued during the
import. Missing columns are named X1, X2, …, Xn in increasing order
for the duration of the Lisp-Stat session.
This column is actually the row name, so we’ll rename it:
The keys of a data frame are symbols, so you need to quote them to prevent the reader from trying to evaluate them to a value.
Note that your row may be named something other than X1, depending
on whether or not you have loaded any other data frames with variable
name replacement. Also note: the ! at the end of the function
name. This is a convention indicating a destructive operation; a copy
will not be returned, it’s the actual data that will be modified.
Now let’s view the results:
Column names
To see the names of the columns, use the column-names function:
Remember we mentioned that the keys (column names) are symbols? Compare the above to the keys of the data frame:
These symbols are printed without double quotes. If a function takes
a key, it must be quoted, e.g. 'mpg and not mpg or "mpg"
Dimensions
We saw the dimensions above in basic information. That was a printed
for human consumption. To get the values in a form suitable for
passing to other functions, use the dims command:
Common Lisp specifies dimensions in row-column order, so mtcars has
32 rows and 12 columns.
Note
Lisp-Stat generally follows the tidyverse philosophy when it comes to row names. By definition, row names are unique, so there is no point including them in a statistical analysis. Nevertheless, many data sets include row names, so we include some special handling for columns with all distinct values; they are excluded by default from summaries (and you can include it if you wish). There is no concept of independent row names as with a R data frame. A Lisp-Stat data frame is more like a tibble.Basic Statistics
Minimum & Maximum
To get the minimum or maximum of a column, say mpg, you can use several
Common Lisp methods. Let’s see what mpg looks like by typing
the name of the column into the REPL:
You could, for example, use something like this to find the minimum:
or the Lisp-Stat function seq-max to find the maximum
or perhaps you’d prefer alexandria:extremum, a general-purpose tool to find the minimum in a different way:
The important thing to note is that mtcars:mpg is a standard Common
Lisp vector and you can manipulate it like one.
Mean & standard deviation
Summarise
You can summarise a column with the summarize-column function:
or the entire data frame:
Recall that the column named model is treated specially, notice
that it is not included in the summary. You can see why it’s excluded
by examining the column’s summary:
Columns with unique values in each row aren’t very interesting.
Saving data
To save a data frame to a CSV file, use the write-csv
method. Here we save mtcars into the Lisp-Stat datasets directory,
including the column names:
3 - Plotting
The basics of plotting
Overview
The plot system provides a way to generate specifications for
plotting applications. Examples of plotting packages include
gnuplot, plotly and
vega/vega-lite.
Plot includes a back end for Vega-Lite; this tutorial will teach you
how to encode Vega-Lite plot specifications using Common Lisp. For
help on Vega-Lite, see the Vega-Lite
tutorials.
For the most part, you can transcribe a Vega-Lite specification directly into Common Lisp and adapt it for your own plots.
Preliminaries
Load Vega-Lite
Load Vega-Lite and network libraries:
and change to the Lisp-Stat user package:
Load example data
The examples in this section use the vega-lite data sets. Load them all now:
Note
If you get an error related tocl-date-time-parser or chroncity (only seen on Allegro Common Lisp), then load them manually with (ql:quickload :cl-date-time-parser) and (ql:quickload :chronicity) and re-run (vega:load-vega-examples)
Anatomy of a spec
Plot takes advantage of the fact that Vega-Lite’s JSON specification
is very close to that of a plist. If you are familiar with Common
Lisp’s ASDF system, then you will be familiar with plot’s way of
specifying graphics (plot was modeled on ASDF).
Let’s look at a Vega-Lite scatterplot example:
and compare it with the equivalent Lisp-Stat version:
Note that in the Lisp-Stat version we are embedding the data
using the :values keyword, as opposed to obtaining it from a server
with :url. You can try plotting this now: click on the copy button
in the upper right corner of the code box and paste it into the REPL.
You should see a window open with the plot displayed:
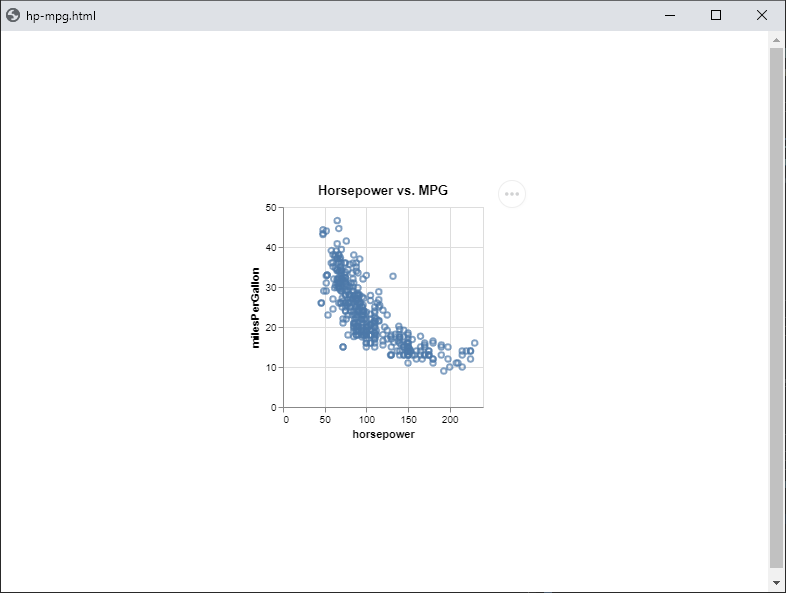
Your first plot
Data sources
The data property
tells Vega where the data for the plot is. Most, but not all,
specifications have a single, top level data property, e.g.
Lisp-Stat allows you to use a data-frame, or data-frame
transformation (filter, selection, etc) as the value for the
data property. For example, since a data-frame transformation
returns a data-frame, we can insert the results as the data value,
as in this plot of residuals:
where we remove :NA and any release-date after 2018.
Vega has
transformations
as well, but are a bit clumsy compared to those in Lisp-Stat.
Sometimes though, you’ll need them because a particular transformation
is not something you want to do to your data-frame. You can mix
transformations in a single plot, as we saw above in the residuals
plot, where the filtering was done in your data-frame and the
transformation was done in vega-lite.
Below are several examples of the hp-mpg plot, using various data sources:
Embedded
Most of the examples in this documentation use embedded data, where the data is a part of the plot specification. For completeness sake, we repeat an example here:
URL
Note in this example we do not use a data frame as a source, therefore we have to specify field encodings as strings, since variable names will not have been converted to idiomatic lisp. E.g. Miles_per_Gallon vs miles-per-gallon.
In a production environment, you may have several quri data sources in your image. To load from one of these:
Here we create the quri object at the same time, since it’s a stand-alone example. It would probably already be created in an actual use case.
Named data
Vega has named data sources that are useful if you have to refer to the same data in several places. We can create one like this:
Plot specifications
Lisp in a spec
A plot specification is a plist. A nested plist to be exact
(or, perhaps more correctly, a tree). This means that we can use
Common Lisp tree/list functions to manipulate it.
If you look carefully at the examples, you’ll note they use a
backquote
(`) instead of a normal list quote ('). This is the mechanism
that Common Lisp
macros use to
rewrite code before compilation, and we can use the same mechanism to
rewrite our Vega-Lite specifications before encoding them.
The simplest, and most common, feature is insertion, like we did
above. By placing a comma (,) before the name of the data frame, we
told the backquote system to insert the value of the data frame
instead of the symbol (vgcars) in the example.
There’s a lot more you can do with the backquote mechanism. We won’t say any more here, as it’s mostly a topic for advanced users. It’s important for you to know it’s there though.
Properties
properties are the keys in key/value pairs. This is true whether
discussing a plist or JSON specification. Vega-Lite is case
sensitive and Common Lisp is not, so there are a few rules you need to
be aware of when constructing plot specifications.
Keys vs. values
Plot uses yason to transform a
plist plot specification to JSON. When yason encodes a spec
there are two functions of importance:
*symbol-encoder**symbol-key-encoder*
The former encodes values, and the latter encodes keys. In
PLOT, both of these are bound to a custom function
encode-symbol-as-metadata. This function does more than just encode
meta data though, it also handles naming conventions.
This won’t mean much in your day-to-day use of the system, but you do need to be aware of the difference between encoding a key and a value. There are some values that the encoder can’t work with, and in those cases you’ll need to use text.
Finally, remember that the symbol encoders are just a convenience to make things more lisp-like. You can build a plot specification, both keys and values, entirely from text if you wish.
Encoding symbols
JavaScript identifiers are incompatible with Common Lisp identifiers,
so we need a way to translate between them. plot uses Parenscript
symbol
conversion
for this. This is one of the reasons for specialised symbol encoders.
Let’s look at the difference between the standard yason encoder and
the one provided by plot (Parenscript):
That difference is significant to Vega-Lite, where identifiers with a
- are not allowed. Vega is also case sensitive, so if a key is
xOffset, xoffset will not work. Fortunately Parenscript’s symbol
conversion is just what we need. It will automatically capitalise the
words following a dash, so x-offset becomes xOffset.
Symbols can also be used for value fields, and these are more forgiving. As long as you are consistent, and keep in mind that a behind the scenes conversion is happening, you can use lisp-like identifiers. Where this mostly comes into play is when you are using Vega transforms, as in the residuals example:
Notice that we used :imdb-rating as the field name for the
joinaggregate, however in the calculate part of the transform we
used the converted name imdbRating; that’s because by the time the
transform is run, the conversion will have already happened. When we
use :as we are assigning a name, when we use datum, we are
telling Vega to find a name, and since this is done in a text
field, plot won’t convert the names it finds inside text strings.
Finally, remember that the Parenscript transformation is also run on
variable/column names. You can see that we referred to imdb-rating
in the filter. If you get confused, run (keys <data-frame>) and
think about how ps:symbol-to-js-string would return the keys.
That’s what Vega will use as the column names.
This is more complicated to explain than to use. See the examples for best practice patterns. You’ll probably only need to be aware of this when doing transforms in Vega.
Variable symbols
When you define a data frame using the defdf macro, Lisp-Stat sets
up an environment for that data set. Part of that environment
includes configuring a package with a symbol for each variable in the
data set. These symbols have properties that describe the variable,
such as unit, label, type, etc. plot can make use of this
information when creating plots. Here’s a previous example, where we
do not use variable symbols:
and one where we do:
The difference is subtle, but this can save some typing if you are always adding titles and field types. We don’t use this in the examples because we want to demonstrate the lowest common denominator, but in all plots we create professionally we use variable symbols.
Special characters
There are occasions when neither the Parenscript encoder nor Yason
will correctly encode a key or value. In those situations, you’ll
need to use text strings. This can happen when Vega wants an encoding
that includes a character that is a reader macro, #, often used in
color specifications, or in format properties, like this one
(:format ".1~%")
Finally, there may be times when you need to use multiple escape
characters
instead of quoted strings. Occasionally an imported data set will
include parenthesis (). The data-frame reader will enclose these
in multiple escape characters, so for example a variable named body mass (g) will be loaded as |BODY-MASS-(G)|. In these cases you can
either change the name to a valid Common Lisp identifier using
rename-column!, or refer to the variable using the multiple escape
characters.
nil, null, false, true
Strictly speaking, false in JavaScript is the Boolean negative. In
practice, "false", a string, is often accepted. This seems to vary
within Vega-Lite. Some parts accept "false", others do not. The
plot symbol encoder will correctly output false for the symbol
:false, and you should use that anywhere you encounter a Boolean
negative.
true is encoded for the lisp symbol T.
nil and null may be entered directly as they are and will be
correctly transcribed.
Embedded data
By default, plot embeds data within the Vega-Lite JSON spec, then
uses vega-embed to display it
within an HTML page. The alternative is to use data from a
url. Both are
mostly equivalent, however there can be differences in parsing,
especially with dates. When data is embedded, values are parsed by
the JavaScript parse in your browser. When it’s loaded via a url,
it’s run through the Vega-Lite parser. Sometimes Vega-Lite needs a
bit of help by way
of format for
embedded data. For this reason plot always outputs dates & times in
ISO-8601 format, which works everywhere.
Large data sets can be problematic if you have a number of plots open and limited memory.
Saving plots
You can save plot specifications like any other Common Lisp object,
for example using with-open-file. data-frames also have read/write
functions. This section describes some convenience functions for plot
I/O.
Devices
A ‘device’ is a loose abstraction for the various locations that data
and specifications can be written to. For example in developing this
website, data is written to a directory for static files
/static/data/, and the plot specification to /static/plots/. We
can model this with a plist like so:
With this ‘device’, you can save a plot like so:
and all the bits will be saved to their proper locations. See the
examples at the bottom of the file PLOT:SRC;VEGA;device.lisp for
various ways to use devices and the heuristics for determining
where/when/what to write. These devices have worked in practice in
generating more than 300 plots, but if you encounter a use case that’s
not covered, please open an
issue.
Vega quirks
Vega and Vega-Lite have more than their fair share of quirks and inconsistencies. For the most part you’ll only notice this in the ‘grammar’ of the graphics specification, however occasionally they may look like bugs.
When using the bin transformation, Vega-Lite assumes that if you
don’t provide the variable identifier to store the end of the bin, it
will use the name of the start of the bin, suffixed with _end. Many
of the Vega-Lite examples make this assumption. For example, this is
the snippet from a Vega-Lite example:
Noticed the bin is using as: bin_Horsepower and then later, in
the groupBy transformation, referring to bin_Horsepower_end. To
work around this ‘feature’, we need to specify both the start and end
for the bin operation:
This kind of behaviour may occur elsewhere, and it’s not well
documented, so just be careful when you see any kind of beginning or
end encoding in a Vega-Lite example.
Workflow
There are many possible workflows when plotting. This section describes a few that I’ve found useful when developing plots.
By default, plot will embed data in an HTML file and then call the
systems browser to open it. This is a perfectly fine way to develop plots,
especially if you’re on a machine with a good amount of RAM.
Vega-Desktop
The Vega-Desktop sadly now unmaintained, still works fine for Vega-Lite up to version 5. With this desktop application, you can drag a plot specification to the application and ‘watch’ it. Once watched, any changes you make are instantly updated in the application window. Here’s a demonstration:
First, set up a ‘device’ to use a directory on the desktop for plotting:
Now send a scatterplot to this device:
Now drag the file ~/Desktop/plots/hp-mpg.vl.json to the Vega-Desktop
application:
and click on the ‘watch’ button:
now go back to the buffer with the spec and add a title:
and reevaluate the form. If you’re in emacs, this is the C-x C-e
command. Observe how the plot is instantly updated:
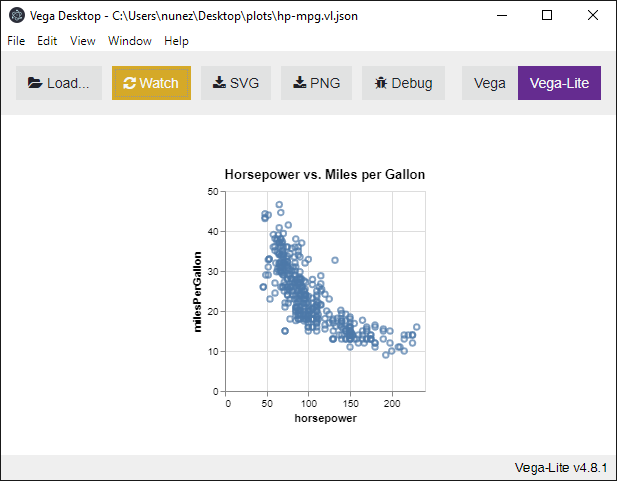
I tend to use this method when I’m tweaking a plot for final publication.
Vega edit
You can publish a plot specification to a Github gist and then invoke the Vega editor. This isn’t quite as real-time as Vega Desktop in that changes in the Lisp image aren’t automatically reflected and you’ll have to re-publish. It is a good way to debug plots and download them in various formats, or for sharing.
To use this mechanism, you’ll need to configure two environment variables so the gist wrapper will be able to use your credentials to authenticate to the Github API. Set the following environment variables to hold your github credentials:
- GITHUB_USERNAME
- GITHUB_OAUTH_TOKEN
Github no longer works with a password, so don’t bother setting that. If you want a custom scheme for authentication, you can create one by following the examples in examples/1.credentials.lisp
Now, you can edit the hp-mpg plot online with:
Debugging
There are a couple of commonly encountered scenarios when plots don’t display correctly:
- it’s so broken the browser displays nothing
- the
...button appears, but the plot is broken
Nothing is displayed
In this case, your best option is to print to a device where you can
examine the output. I use the Vega-Desktop (vgdsk1) so often it’s
part of my Lisp-Stat initialisation, and I also use it for these
cases. Once you’ve got the spec written out as JSON, see if
Vega-Desktop can render it, paying attention to the warnings.
Vega-Desktop also has a debug function:
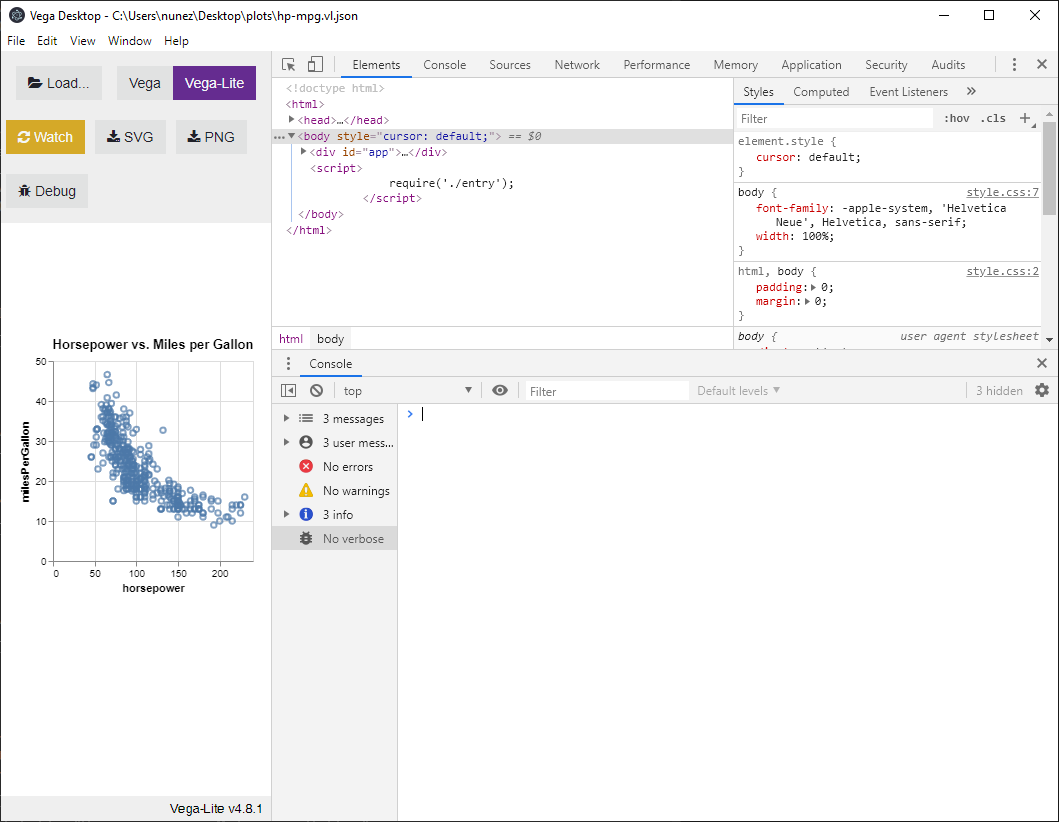
If Vega-Desktop doesn’t help, open the file in Visual Studio code, which has a schema validator. Generally these kinds of syntax errors are easy to spot once they’re pointed out by Visual Studio.
Something is displayed
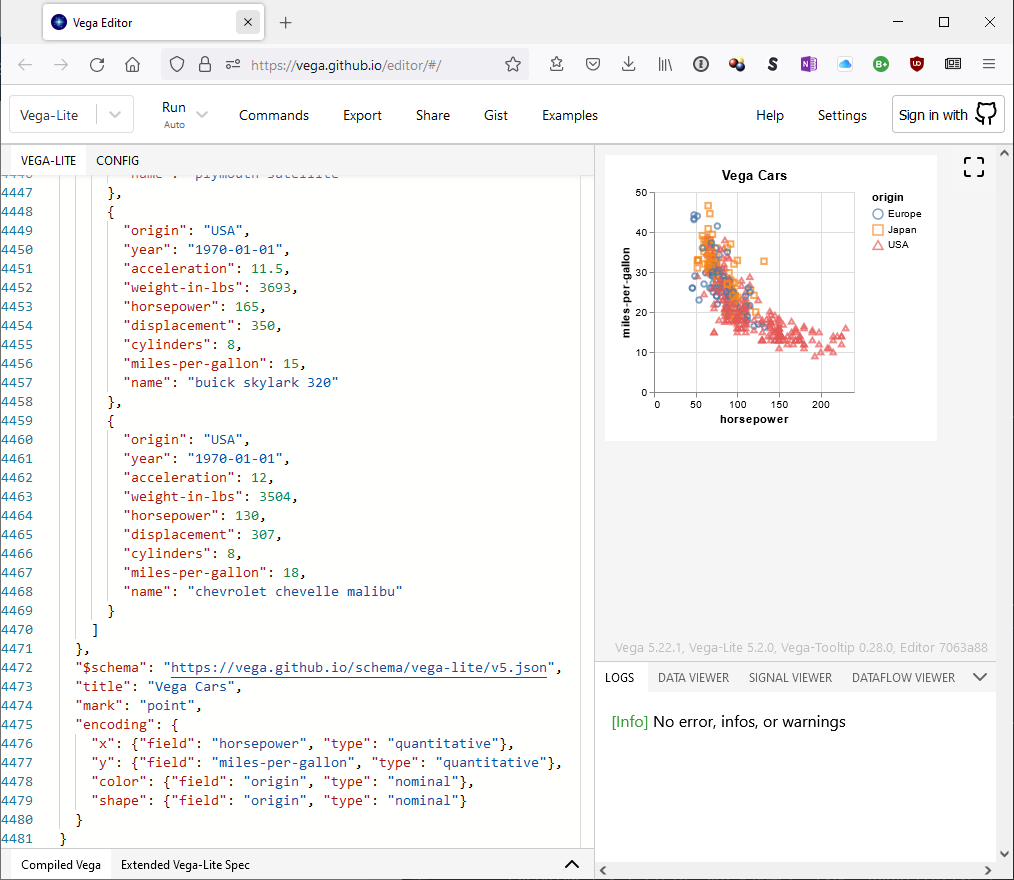
If you see the three ellipses, then you can open the plot in the online vega editor. This is very similar to Vega Desktop, but with one important difference: you can only debug plots with embedded data sets or remotely available URLs. Because the online editor is a web application hosted on Github, you can’t access local data sets. This is one reason I typically use the Vega-Desktop / Visual Studio combination.
Getting plot information
There are two ways to get information about the plots in your environment.
show-plots
The show-plots command will display the plots you have defined,
along with a description (if one was provided in the spec). Here are
the plots currently in my environment:
Only the last, from the example above, has a description.
describe
You can also use the describe command to view plot information:
inspect
By typing the plots name in the emacs REPL, a ‘handle’ of sorts is returned, printed in orange:

Right click on the orange text to get a context menu allowing various operations on the object, one of which is to ‘inspect’ the object.
Included datasets
The vega package includes all the data sets in the vega data
sets. They
have the same name, in the vega package, e.g. vega:penguins.