This section contains user documentation for Lisp-Stat. It is designed for technical users who wish to understand how to use Lisp-Stat to perform statistical analysis.
Other content such as marketing material, case studies, and community updates are in the About and Community pages.
1 - What is Lisp-Stat?
A statistical computing environment written in Common Lisp
Lisp-Stat is a domain specific language (DSL) for statistical analysis
and machine learning. It is targeted at statistics practitioners with
little or no experience in programming.
Relationship to XLISP-Stat
Although inspired by Tierney’s XLisp-Stat, this is a reboot in Common
Lisp. XLisp-Stat code is unlikely to run except in trivial cases.
Existing XLisp-Stat libraries can be ported with the assistance of the
XLS-Compat system.
Core Systems
Lisp-Stat is composed of several systems (projects), each
independently useful and brought together under the Lisp-Stat
umbrella. Dependencies between systems have been minimised to the
extent possible so you can use them individually without importing all
of Lisp-Stat.
Data-Frame
A data frame is a data structure conceptually similar to a R data
frame.
It provides column-centric storage for data sets where each named
column contains the values for one variable, and each row contains one
set of observations. For data frames, we use the
‘tibble’
from the tidyverse as inspiration for
functionality.
Data frames can contain values of any type. If desired, additional
attributes, such as the numerical type, unit and other information may be
attached to the variable for convenience or efficiency. For example
you could specify a unit of length, say m/s (meters per second), to
ensure that mathematical operations on that variable always produce
lengths (though the unit may change).
DFIO
The Data Frame I/O system provides input and output operations for
data frames. A data frame may be written to and read from files,
strings or streams, including network streams or relational databases.
Select
Select is a facility for selecting portions of sequences or arrays. It provides:
An API for making selections (elements selected by the Cartesian
product of vectors of subscripts for each axis) of array-like
objects. The most important function is select. Unless you want
to define additional methods for select, this is pretty much all
you need from this library.
An extensible DSL for selecting a subset of valid subscripts. This
is useful if, for example, you want to resolve column names in a
data frame in your implementation of select, or implementing
filtering based on row values.
Array Operations
This library is a collection of functions and macros for manipulating
Common Lisp arrays and performing numerical calculations with
them. The library provides shorthand codes for frequently used
operations, displaced array functions, indexing, transformations,
generation, permutation and reduction of columns. Array operations
may also be applied to data frames, and data frames may be converted
to/from arrays.
Special Functions
This library implements numerical special
functions in Common
Lisp with a focus on high accuracy double-float calculations. These
functions are the basis for the statistical distributions functions,
e.g. gamma, beta, etc.
Cephes
Cephes.cl is a CFFI wrapper
over the Cephes Math Library, a high quality C implementation of
statistical functions. We use this both for an accuracy check (Boost
uses these to check its accuracy too), and to fill in the gaps where
we don’t yet have common lisp implementations of these functions.
Numerical Utilities
Numerical Utilities is the
base system that most others depend on. It is a collection of packages
providing:
num=, et. al. comparison operators for floats
simple arithmetic functions, like sum and l2norm
element-wise operations for arrays and vectors
intervals
special matrices and shorthand for their input
sample statistics
Chebyshev polynomials
quadratures
univariate root finding
horner’s, simpson’s and other functions for numerical analysis
Lisp-Stat
This is the top level system that uses the other packages to create a
statistical computing environment. It is also the location for the
‘unified’ interface, where the holes are plugged with third party
packages. For example
cl-mathstats contains
functionality not yet in Lisp-Stat, however its architecture does not
lend itself well to incorporation via an ASDF depends-on, so as we
consolidate the libraries, missing functionality will be placed in the
Lisp-Stat system. Eventually parts of numerical-utilities,
especially the statistics functions, will be relocated here.
Acknowledgements
Tamas Papp was the original author of many of these
libraries. Starting with relatively clean, working, code that solves
real-world problems was a great start to the development of Lisp-Stat.
If you have a working installation of SBCL, Google Chrome and
Quicklisp you can be up and running in 5 minutes.
Prerequisites
Steel Bank Common Lisp (SBCL) or CCL
MacOS, Linux or Windows 10+
Quicklisp
Chrome, Firefox or Edge
Loading
First load Lisp-Stat, Plot and sample data. We will use Quicklisp for
this, which will both download the system if it isn’t already
available, and compile and load it.
Lisp-Stat
(ql:quickload :lisp-stat)
(in-package :ls-user) ;access to Lisp-Stat functions
Plotting
(ql:quickload :plot/vega)
Data
(data :vgcars)
View
Print the vgcars data-frame (showing the first 25 rows by default)
(print-data vgcars)
;; ORIGIN YEAR ACCELERATION WEIGHT_IN_LBS HORSEPOWER DISPLACEMENT CYLINDERS MILES_PER_GALLON NAME
;; USA 1970-01-01 12.0 3504 130 307.0 8 18.0 chevrolet chevelle malibu
;; USA 1970-01-01 11.5 3693 165 350.0 8 15.0 buick skylark 320
;; USA 1970-01-01 11.0 3436 150 318.0 8 18.0 plymouth satellite
;; USA 1970-01-01 12.0 3433 150 304.0 8 16.0 amc rebel sst
;; USA 1970-01-01 10.5 3449 140 302.0 8 17.0 ford torino
;; USA 1970-01-01 10.0 4341 198 429.0 8 15.0 ford galaxie 500
;; USA 1970-01-01 9.0 4354 220 454.0 8 14.0 chevrolet impala
;; USA 1970-01-01 8.5 4312 215 440.0 8 14.0 plymouth fury iii
;; USA 1970-01-01 10.0 4425 225 455.0 8 14.0 pontiac catalina
;; USA 1970-01-01 8.5 3850 190 390.0 8 15.0 amc ambassador dpl
;; Europe 1970-01-01 17.5 3090 115 133.0 4 NIL citroen ds-21 pallas
;; USA 1970-01-01 11.5 4142 165 350.0 8 NIL chevrolet chevelle concours (sw)
;; USA 1970-01-01 11.0 4034 153 351.0 8 NIL ford torino (sw)
;; USA 1970-01-01 10.5 4166 175 383.0 8 NIL plymouth satellite (sw)
;; USA 1970-01-01 11.0 3850 175 360.0 8 NIL amc rebel sst (sw)
;; USA 1970-01-01 10.0 3563 170 383.0 8 15.0 dodge challenger se
;; USA 1970-01-01 8.0 3609 160 340.0 8 14.0 plymouth 'cuda 340
;; USA 1970-01-01 8.0 3353 140 302.0 8 NIL ford mustang boss 302
;; USA 1970-01-01 9.5 3761 150 400.0 8 15.0 chevrolet monte carlo
;; USA 1970-01-01 10.0 3086 225 455.0 8 14.0 buick estate wagon (sw)
;; Japan 1970-01-01 15.0 2372 95 113.0 4 24.0 toyota corona mark ii
;; USA 1970-01-01 15.5 2833 95 198.0 6 22.0 plymouth duster
;; USA 1970-01-01 15.5 2774 97 199.0 6 18.0 amc hornet
;; USA 1970-01-01 16.0 2587 85 200.0 6 21.0 ford maverick ..
Show the last few rows:
(tail vgcars)
;; ORIGIN YEAR ACCELERATION WEIGHT_IN_LBS HORSEPOWER DISPLACEMENT CYLINDERS MILES_PER_GALLON NAME
;; USA 1982-01-01 17.3 2950 90 151 4 27 chevrolet camaro
;; USA 1982-01-01 15.6 2790 86 140 4 27 ford mustang gl
;; Europe 1982-01-01 24.6 2130 52 97 4 44 vw pickup
;; USA 1982-01-01 11.6 2295 84 135 4 32 dodge rampage
;; USA 1982-01-01 18.6 2625 79 120 4 28 ford ranger
;; USA 1982-01-01 19.4 2720 82 119 4 31 chevy s-10
Statistics
Look at a few statistics on the data set.
(mean vgcars:acceleration) ; => 15.5197
The summary command, that works in data frames or individual variables, summarises the variable. Below is a summary with some variables elided.
LS-USER> (summary vgcars)
"ORIGIN": 254 (63%) x "USA", 79 (19%) x "Japan", 73 (18%) x "Europe"
"YEAR": 61 (15%) x "1982-01-01", 40 (10%) x "1973-01-01", 36 (9%) x "1978-01-01", 35 (9%) x "1970-01-01", 34 (8%) x "1976-01-01", 30 (7%) x "1975-01-01", 29 (7%) x "1971-01-01", 29 (7%) x "1979-01-01", 29 (7%) x "1980-01-01", 28 (7%) x "1972-01-01", 28 (7%) x "1977-01-01", 27 (7%) x "1974-01-01"
ACCELERATION (1/4 mile time)
n: 406
missing: 0
min=8
q25=13.67
q50=15.45
mean=15.52
q75=17.17
max=24.80
WEIGHT-IN-LBS (Weight in lbs)
n: 406
missing: 0
min=1613
q25=2226
q50=2822.50
mean=2979.41
q75=3620
max=5140
...
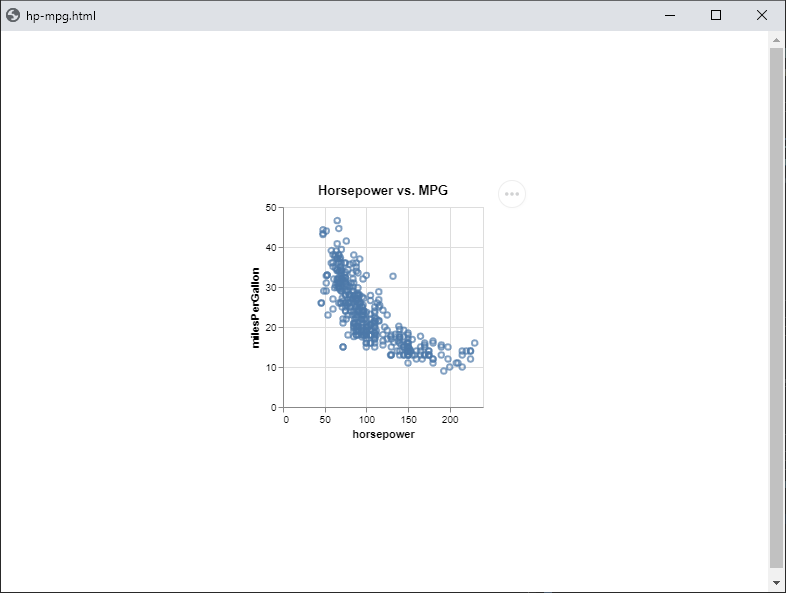
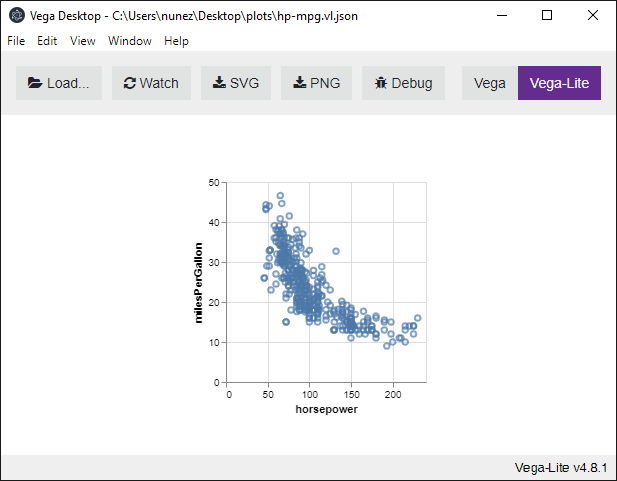
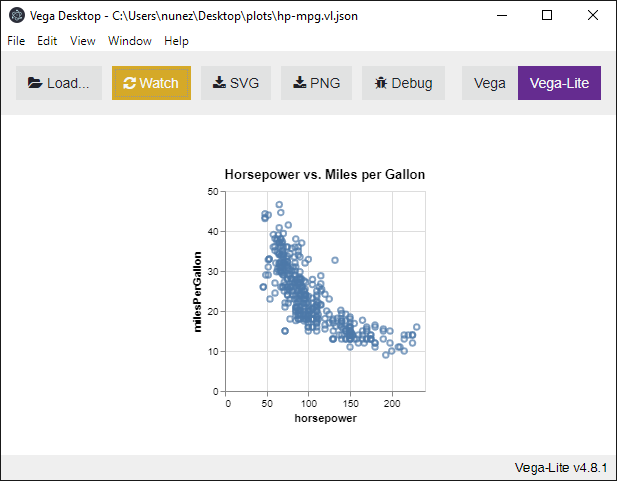
Plot
Create a scatter plot specification comparing horsepower and miles per
gallon:
(plot:plot
(vega:defplot hp-mpg
`(:title "Horsepower vs. MPG"
:description "Horsepower vs miles per gallon for various cars"
:data (:values ,vgcars)
:mark :point
:encoding (:x (:field :horsepower :type :quantitative)
:y (:field :miles-per-gallon :type :quantitative)))))
2.1 - Installation
Installing and configuring Lisp-Stat
New to Lisp
If you are a Lisp newbie and want to get started as fast as possible,
then Portacle is your best option. Portacle is a multi-platform IDE
for Common Lisp that includes Emacs, SBCL, Git, Quicklisp, all
configured and ready to use.
Users new to lisp should also consider going through the Lisp-Stat
basic tutorial, which guides you
step-by-step through the basics of working with Lisp as a statistics
practitioner.
We assume an experienced user will have their own Emacs and lisp
implementation and will want to install according to their own tastes
and setup. The repo links you need are below, or you can install with
clpm or quicklisp.
Prerequisites
All that is needed is an ANSI Common Lisp implementation. Development
is done with Genera and SBCL. Other platforms should work, but will
not have been tested, nor can we offer support (maintaining & testing
on multiple implementations requires more resources than the project
has available). Note that CCL is not in good health, and there are a
few numerical bugs that remain unfixed. A shame, as we really liked
CCL.
Installation
The easiest way to install Lisp-Stat is via
Quicklisp, a library manager for
Common Lisp. It works with your existing Common Lisp implementation to
download, install, and load any of over 1,500 libraries with a few
simple commands.
Quicklisp is like a package manager in Linux. It can load packages
from the local file system, or download them if required. If you have
quicklisp installed, you can use:
(ql:quickload :lisp-stat)
Quicklisp is good at managing the project dependency retrieval, but
most of the time we use ASDF because of its REPL integration. You only
have to use Quicklisp once to get the dependencies, then use ASDF for
day-to-day work.
You can install additional Lisp-Stat modules in the same way. For example to install the SQLDF module:
(ql:quickload :sqldf)
Loading
Once you have obtained Lisp-Stat via Quicklisp, you can load in one of two ways:
ASDF
Quicklisp
Loading with ASDF
(asdf:load-system :lisp-stat)
If you are using emacs, you can use the slime
shortcuts to
load systems by typing , and then load-system in the mini-buffer.
This is what the Lisp-Stat developers use most often, the shortcuts
are a helpful part of the workflow.
Loading with Quicklisp
To load with Quicklisp:
(ql:quickload :lisp-stat)
Quicklisp uses the same ASDF command as above to load Lisp-Stat.
Updating Lisp-Stat
When a new release is announced, you can update via Quicklisp like so:
(ql:update-dist "lisp-stat")
IDEs
There are a couple of IDE’s to consider:
Emacs
Emacs, with the slime
package is the most tested IDE and the one the authors use. If you
are using one of the starter lisp packages mentioned in the getting
started section, this will have
been installed for you. Otherwise, slime/swank is available in
quicklisp and clpm.
Jupyter Lab
Jupyter Lab and
common-lisp-jupyter
provide an environment similar to RStudio for working with data and
performing analysis. The Lisp-Stat analytics
examples use Jupyter Lab to illustrate
worked examples based on the book, Introduction to the Practice of
Statistics.
Visual Studio Code
This is a very popular IDE, with improving support for Common Lisp.
If you already use this editor, it is worth investigating to see if
the Lisp support is sufficient for you to perform an analysis.
Documentation
You can install the info manuals into the emacs help system and this
allows searching and browsing from within the editing environment. To
do this, use the
install-info
command. As an example, on my MS Windows 10 machine, with MSYS2/emacs
installation:
installs the select manual at the top level of the info tree. You
can also install the common lisp hyperspec and browse documentation
for the base Common Lisp system. This really is the best way to use
documentation whilst programming Common Lisp and Lisp-Stat. See the
emacs external
documentation
and “How do I install a piece of Texinfo
documentation?”
for more information on installing help files in emacs.
See getting help for
information on how to access Info documentation as you code. This is
the mechanism used by Lisp-Stat developers because you don’t have to
leave the emacs editor to look up function documentation in a browser.
Initialization file
You can put customisations to your environment in either your
implementation’s init file, or in a personal init file and load it
from the implementation’s init file. For example, I keep my
customisations in #P"~/ls-init.lisp" and load it from SBCL’s init
file ~/.sbclrc in a Lisp-Stat initialisation section like this:
Settings in your personal lisp-stat init file override the system defaults.
Here’s an example ls-init.lisp file that loads some common R data sets:
(defparameter *default-datasets*
'("tooth-growth" "plant-growth" "usarrests" "iris" "mtcars")
"Data sets loaded as part of personal Lisp-Stat initialisation.
Available in every session.")
(map nil #'(lambda (x)
(format t "Loading ~A~%" x)
(data x))
*default-datasets*)
With this init file, you can immediately access the data sets in the
*default-datasets* list defined above, e.g.:
This manual is organised by audience. The overview
and getting started sections are applicable
to all users. Other sections are focused on statistical practitioners,
developers or users new to Common Lisp.
Examples
This part of the documentation contains worked examples of statistical
analysis and plotting. It has less explanatory material, and more
worked examples of code than other sections. If you have a common
use-case and want to know how to solve it, look here.
Tutorials
This section contains tutorials, primers and ‘vignettes’. Typically
tutorials contain more explanatory material, whilst primers are
short-form tutorials on a particular system.
System manuals
The manuals are written at a level somewhere between an API reference
and a core task. They document, with text and examples, the core APIs
of each system. These are useful references for power users,
developers and if you need to go a bit beyond the core tasks.
Reference
The reference manuals document the API for each system. These are
typically used by developers building extensions to Lisp-Stat.
Resources
Common Lisp and statistical resources, such as books, tutorials and
website. Not specific to Lisp-Stat, but useful for statistical
practitioners learning Lisp.
Contributing
This section describes how to contribute to Lisp-Stat. There are both
ideas on what to contribute, as well as instructions on how to
contribute. Also note the section on the top right of all the
documentation pages, just below the search box:
If you see a mistake in the documentation, please use the Create documentation issue link to go directly to github and report the
error.
2.3 - Getting Help
Ways to get help with Lisp-Stat
There are several ways to get help with Lisp-Stat and your statistical
analysis. This section describes way to get help with your data
objects, with Lisp-Stat commands to process them, and with Common
Lisp.
Search
We use the algolia search engine to index
the site. This search engine is specialised to work well with
documentation websites like this one. If you’re looking for something
and can’t find it in the navigation panes, use the search box:
Apropos
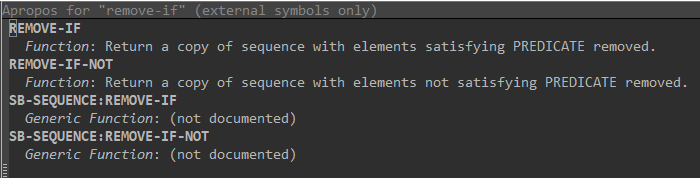
If you’re not quite sure what you’re looking for, you can use the
apropos command. You can do this either from the REPL or emacs.
Here are two examples:
This works even better using emacs/slime. If you use the slime command sequence C-c C-d a, (all the slime documentation commands start with C-c C-d) emacs will ask you for a string. Let’s say you typed in remove-if. Emacs will open a buffer like the one below with all the docs strings for similar functions or variables:
Restart from errors
Common lisp has what is called a condition system, which is somewhat unique. One of the features of the condition system is something call restarts. Basically, one part of the system can signal a condition, and another part of it can handle the condition. One of the ways a signal can be handled is by providing various restarts. Restarts happen by the debugger, and many users new to Common Lisp tend to shy away from the debugger (this is common to other languages too). In Common Lisp the debugger is both for developers and users.
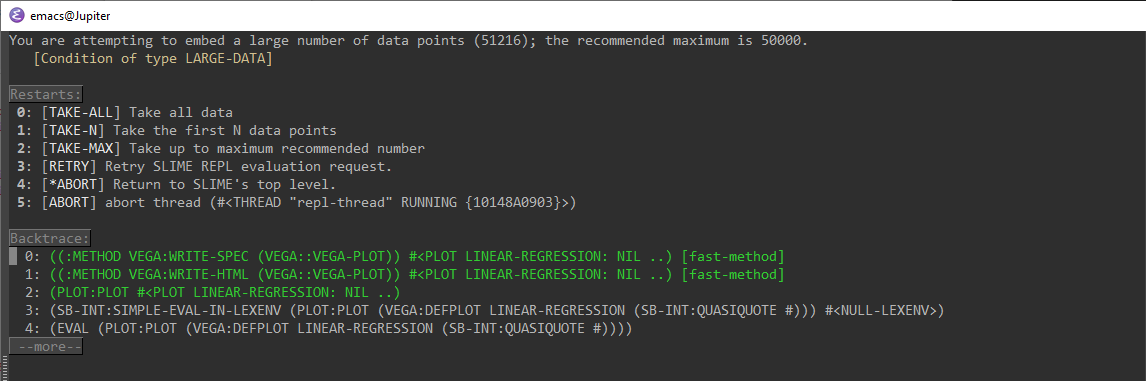
Well written Lisp programs will provide a good set of restarts for commonly encountered situations. As an example, suppose we are plotting a data set that has a large number of data points. Experience has shown that greater than 50,000 data points can cause browser performance issues, so we’ve added a restart to warn you, seen below:
Here you can see we have options to take all the data, take n (that the user will provide) or take up to the maximum recommended number. Always look at the options offered to you by the debugger and see if any of them will fix the problem for you.
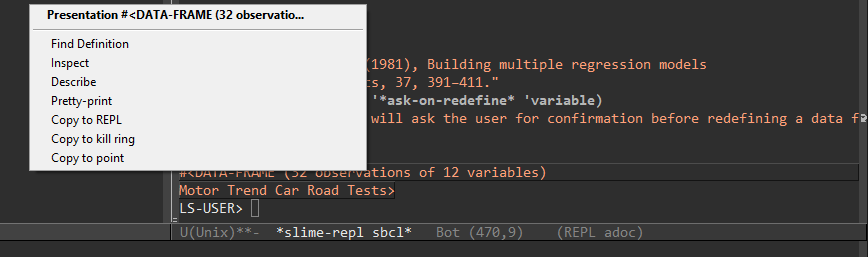
Describe data
You can use the describe command to print a description of just
about anything in the Lisp environment. Lisp-Stat extends this
functionality to describe data. For example:
LS-USER> (describe 'mtcars)
LS-USER::MTCARS
[symbol]
MTCARS names a special variable:
Value: #<DATA-FRAME (32 observations of 12 variables)
Motor Trend Car Road Tests>
Documentation:
Motor Trend Car Road Tests
Description
The data was extracted from the 1974 Motor Trend US magazine, and
comprises fuel consumption and 10 aspects of automobile design and
performance for 32 automobiles (1973–74 models).
Note
Henderson and Velleman (1981) comment in a footnote to Table 1:
‘Hocking [original transcriber]'s noncrucial coding of the Mazda's
rotary engine as a straight six-cylinder engine and the Porsche's
flat engine as a V engine, as well as the inclusion of the diesel
Mercedes 240D, have been retained to enable direct comparisons to
be made with previous analyses.’
Source
Henderson and Velleman (1981), Building multiple regression models
interactively. Biometrics, 37, 391–411.
Variables:
Variable | Type | Unit | Label
-------- | ---- | ---- | -----------
MODEL | STRING | NIL | NIL
MPG | DOUBLE-FLOAT | M/G | Miles/(US) gallon
CYL | INTEGER | NA | Number of cylinders
DISP | DOUBLE-FLOAT | IN3 | Displacement (cu.in.)
HP | INTEGER | HP | Gross horsepower
DRAT | DOUBLE-FLOAT | NA | Rear axle ratio
WT | DOUBLE-FLOAT | LB | Weight (1000 lbs)
QSEC | DOUBLE-FLOAT | S | 1/4 mile time
VS | CATEGORICAL | NA | Engine (0=v-shaped, 1=straight)
AM | CATEGORICAL | NA | Transmission (0=automatic, 1=manual)
GEAR | CATEGORICAL | NA | Number of forward gears
CARB | CATEGORICAL | NA | Number of carburetors
Documentation
The documentation command can be used to read the documentation of a function or variable. Here’s how to read the documentation for the Lisp-Stat mean function:
LS-USER> (documentation 'mean 'function)
"The mean of elements in OBJECT."
You can also view the documentation for variables or data objects:
LS-USER> (documentation '*ask-on-redefine* 'variable)
"If non-nil the system will ask the user for confirmation
before redefining a data frame"
Emacs inspector
When Lisp prints an interesting object to emacs/slime, it will be
displayed in orange text. This indicates that it is a presentation, a
special kind of object that we can manipulate. For example if you type
the name of a data frame, it will return a presentation object:
Now if you right click on this object you’ll get the presentation menu:
From this menu you can go to the source code of the object, inspect &
change values, describe it (as seen above, but within an emacs
window), and copy it.
Slime inspector
The slime
inspector is
an alternative inspector for emacs, with some additional
functionality.
Slime documentation
Slime documentation provides ways to browse documentation from the editor. We saw one example above with apropos. You can also browse variable and function documentation. For example if you have the cursor positioned over a function:
(show-data-frames)
and you type C-c C-d f (describe function at point), you’ll see this
in an emacs window:
#<FUNCTION SHOW-DATA-FRAMES>
[compiled function]
Lambda-list: (&KEY (HEAD NIL) (STREAM *STANDARD-OUTPUT*))
Derived type: (FUNCTION (&KEY (:HEAD T) (:STREAM T)) *)
Documentation:
Print all data frames in the current environment in
reverse order of creation, i.e. most recently created first.
If HEAD is not NIL, print the first six rows, similar to the
HEAD function.
Source file: s:/src/data-frame/src/defdf.lisp
Select a name for your new project and click Create repository from template
Make your own local working copy of your new repo using git clone, replacing https://github.com/me/example.git with your
repo’s URL:
git clone --depth 1 https://github.com/me/example.git
You can now edit your own versions of the project’s source files.
This will clone the project template into your own github repository
so you can begin adding your own files to it.
Directory Structure
By convention, we use a directory structure that looks like this:
Often your project will have sample data used for examples
illustrating how to use the system. Such example data goes here, as
would static data files that your system includes, for example post
codes (zip codes). For some projects, we keep the project data here
too. If the data is obtained over the network or a data base, login
credentials and code related to that is kept here. Basically,
anything neccessary to obtain the data should be kept in this
directory.
src
The lisp source code for loading, cleaning and analysing your data.
If you are using the template for a Lisp-Stat add-on package, the
source code for the functionality goes here.
tests
Tests for your code. We recommend either
CL-UNIT2 or
PARACHUTE for test
frameworks.
docs
Generated documentation goes here. This could be both API
documentation and user guides and manuals. If an index.html file
appears here, github will automatically display it’s contents at
project.github.io, if you have configured the repository to display
documentation that way.
Load your project
If you’ve cloned the project template into your local Common Lisp
directory, ~/common-lisp/, then you can load it with (ql:quickload :project). Lisp will download and compile the neccessary
dependencies and your project will be loaded. The first thing you’ll
want to do is to configure your project.
Configure your project
First, change the directory and repository name to suit your
environment and make sure git remotes are working properly. Save
yourself some time and get git working before configuring the project
further.
ASDF
The project.asd file is the Common Lisp system definition file.
Rename this to be the same as your project directory and edit its
contents to reflect the state of your project. To start with, don’t
change any of the file names; just edit the meta data. As you add or
rename source code files in the project you’ll update the file names
here so Common Lisp will know that to compile. This file is analgous
to a makefile in C – it tells lisp how to build your project.
Initialisation
If you need project-wide initialisation settings, you can do this in
the file src/init.lisp. The template sets up a logical path
name for
the project:
To use it, you’ll modify the directories and project name for your
project, and then call (setup-project-translations) in one of your
lisp initialisation files (either ls-init.lisp or .sbclrc). By
default, the project data directory will be set to a subdirectory
below the main project directory, and you can access files there with
PROJECT:DATA;mtcars.csv for example. When you configure your
logical pathnames, you’ll replace “PROJECT” with your projects name.
We use logical style pathnames throughout the Lisp-Stat documentation,
even if a code level translation isn’t in place.
Basic workflow
The project templates illustrates the basic steps for a simple
analysis.
Load data
The first step is to load data. The PROJECT:SRC;load file shows
creating three data frames, from three different sources: CSV, TSV and
JSON. Use this as a template for loading your own data.
Cleanse data
load.lisp also shows some simple cleansing, adding labels, types and
attributes, and transforming (recoding) a variable. You can follow
these examples for your own data sets, with the goal of creating a
data frame from your data.
Analyse
PROJECT:SRC;analyse shows taking the mean and standard deviation of
the mpg variable of the loaded data set. Your own analysis will, of
course, be different. The examples here are meant to indicate the
purpose. You may have one or more files for your analysis, including
supporting functions, joining data sets, etc.
Plot
Plotting can be useful at any stage of the process. It’s inclusion as
the third step isn’t intended to imply a particular importance or
order. The file PROJECT:SRC;plot shows how to plot the information
in the disasters data frame.
Save
Finally, you’ll want to save your data frame after you’ve got it where
you want it to be. You can save project in a ’native’ format, a lisp
file, that will preserve all your meta data and is editable, or a CSV
file. You should only use a CSV file if you need to use the data in
another system. PROJECT:SRC;save shows how to save your work.
3 - Examples
Using Lisp-Stat in the real world
One of the best ways to learn Lisp-Stat is to see examples of actual work. This section contains examples of performing statistical analysis, derived from the book Introduction to the Practices of Statistics (2017) by Moore, McCabe and Craig and plotting from the Vega-Lite example gallery.
3.1 - Plotting
Example plots
The plots here show equivalents to the Vega-Lite example
gallery. Before you begin working with these example, be certain to read the plotting tutorial where you will learn the basics of working with plot specifications and data.
Preliminaries
Load Vega-Lite
Load Vega-Lite and network libraries:
(asdf:load-system :plot/vega)
and change to the Lisp-Stat user package:
(in-package :ls-user)
Load example data
The examples in this section use the vega-lite data sets. Load them all now:
(vega:load-vega-examples)
Bar charts
Bar charts are used to display information about categorical variables.
Simple bar chart
In this simple bar chart example we’ll demonstrate using literal
embedded data in the form of a plist. Later you’ll see how to use a data-frame directly.
(plot:plot
(vega:defplot simple-bar-chart
`(:mark :bar
:data (:values ,(plist-df '(:a #(A B C D E F G H I)
:b #(28 55 43 91 81 53 19 87 52))))
:encoding (:x (:field :a :type :nominal :axis ("labelAngle" 0))
:y (:field :b :type :quantitative)))))
Grouped bar chart
(plot:plot
(vega:defplot grouped-bar-chart
`(:mark :bar
:data (:values ,(plist-df '(:category #(A A A B B B C C C)
:group #(x y z x y z x y z)
:value #(0.1 0.6 0.9 0.7 0.2 1.1 0.6 0.1 0.2))))
:encoding (:x (:field :category)
:y (:field :value :type :quantitative)
:x-offset (:field :group)
:color (:field group)))))
Stacked bar chart
This example uses Seattle weather from the Vega website. Load it into
a data frame like so:
We’ll use a data-frame as the data source via the Common Lisp
backquote
mechanism.
The spec list begins with a backquote (`) and then the data frame is
inserted as a literal value with a comma (,). We’ll use this
pattern frequently.
Vega calls this a diverging stacked bar
chart.
It is a population pyramid for the US in 2000, created using the
stack feature of
vega-lite. You could also create one using
concat.
First, load the population data if you haven’t done so:
(defdf population (vega:read-vega vega:population))
;=> #<DATA-FRAME (570 observations of 4 variables)>
Note the use of read-vega in this case. This is because the data in
the Vega example is in an application specific JSON format (Vega, of
course).
Use a relative frequency histogram to compare data sets with different
numbers of observations.
The data is binned with first transform. The number of values per bin
and the total number are calculated in the second and the third
transform to calculate the relative frequency in the last
transformation step.
(plot:plot
(vega:defplot stacked-density
`(:title "Distribution of Body Mass of Penguins"
:width 400
:height 80
:data (:values ,penguins)
:mark :bar
:transform #((:density |BODY-MASS-(G)|
:groupby #(:species)
:extent #(2500 6500)))
:encoding (:x (:field :value
:type :quantitative
:title "Body Mass (g)")
:y (:field :density
:type :quantitative
:stack :zero)
:color (:field :species
:type :nominal)))))
Note the use of the multiple escape
characters
(|) surrounding the field BODY-MASS-(G). This is required because
the JSON data set has parenthesis in the variable names, and these are
reserved characters in Common Lisp. The JSON importer wrapped these
in the escape character.
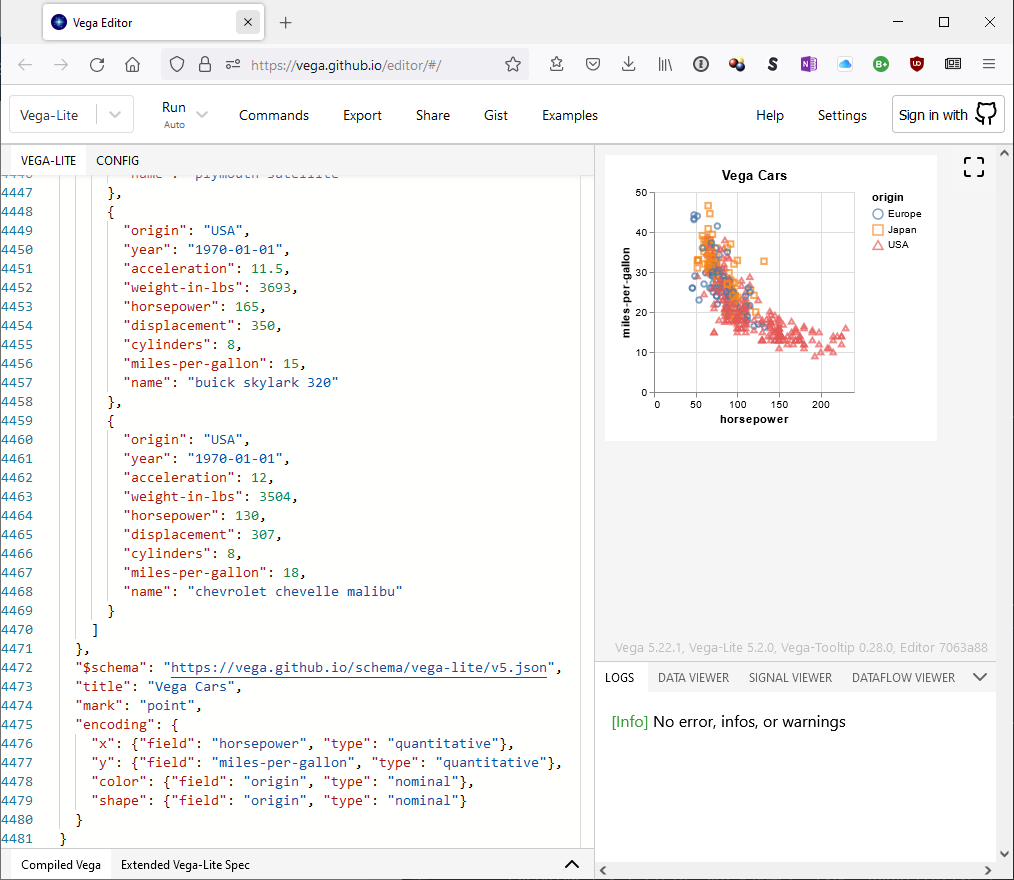
In this example we’ll show how to add additional information to
the cars scatter plot to show the cars origin. The Vega-Lite
example
shows that we have to add two new directives to the encoding of the
plot:
Notice here we use a string for the field value and not a symbol.
This is because Vega is case sensitive, whereas Lisp is not. We could
have also used a lower-case :as value, but did not to highlight this
requirement for certain Vega specifications.
A dot plot showing each film in the database, and the difference from
the average movie rating. The display is sorted by year to visualize
everything in sequential order. The graph is for all films before
2019. Note the use of the filter-rows function.
The cars scatterplot allows you to see miles per gallon
vs. horsepower. By adding sliders, you can select points by the
number of cylinders and year as well, effectively examining 4
dimensions of data. Drag the sliders to highlight different points.
Note how we modified the example by using a lower case entity in the
filter to match our default lower case variable names. Also note how
we are explicit with parsing the year field as a temporal column.
This is because, when creating a chart with inline data, Vega-Lite
will parse the field as an integer instead of a date.
Line plots
Simple
(plot:plot
(vega:defplot simple-line-plot
`(:title "Google's stock price from 2004 to early 2010"
:data (:values ,(filter-rows stocks '(string= symbol "GOOG")))
:mark :line
:encoding (:x (:field :date
:type :temporal)
:y (:field :price
:type :quantitative)))))
Point markers
By setting the point property of the line mark definition to an object
defining a property of the overlaying point marks, we can overlay
point markers on top of line.
This radial plot uses both angular and radial extent to convey
multiple dimensions of data. However, this approach is not
perceptually effective, as viewers will most likely be drawn to the
total area of the shape, conflating the two dimensions. This example
also demonstrates a way to add labels to circular plots.
Normally data transformations should be done in Lisp-Stat with a data
frame. These examples illustrate how to accomplish transformations
using Vega-Lite. This might be useful if, for example, you’re serving
up a lot of plots and want to move the processing to the users
browser.
This example is one of those mentioned in the plotting
tutorial that uses a non-standard location for
the data property.
Weather exploration
This graph shows an interactive view of Seattle’s weather, including
maximum temperature, amount of precipitation, and type of weather. By
clicking and dragging on the scatter plot, you can see the proportion
of days in that range that have sun, rain, fog, snow, etc.
Cross-filtering makes it easier and more intuitive for viewers of a
plot to interact with the data and understand how one metric affects
another. With cross-filtering, you can click a data point in one
dashboard view to have all dashboard views automatically filter on
that value.
Click and drag across one of the charts to see the other variables
filtered.
These notebooks describe how to undertake statistical analyses introduced as examples in the Ninth Edition of Introduction to the Practices of Statistics (2017) by Moore, McCabe and Craig. The notebooks are organised in the same manner as the chapters of the book. The data comes from the site IPS9 in R by Nicholas Horton.
After installing cl-jupyter, clone the IPS repository into your ~/common-lisp/ directory.
Note
Be careful when upgrading common-lisp-jupyter. Breaking changes are often introduced without warning. If you experience problems, use cl-jupyter revision b1021ab by using the git checkout command.
These learning tutorials demonstrate how to perform end-to-end
statistical analysis of sample data using Lisp-Stat. Sample data is
provided for both the examples and the optional exercises. By
completing these tutorials you will understand the tasks required for
a typical statistical workflow.
4.1 - Basics
An introduction to the basics of LISP-STAT
Preface
This document is intended to be a tutorial introduction to the basics
of LISP-STAT and is based on the original tutorial for XLISP-STAT
written by Luke Tierney, updated for Common Lisp and the 2021
implementation of LISP-STAT.
LISP-STAT is a statistical environment built on top of the Common Lisp
general purpose programming language. The first three sections
contain the information you will need to do elementary statistical
calculations and plotting. The fourth section introduces some
additional methods for generating and modifying data. The fifth
section describes some features of the user interface that may be
helpful. The remaining sections deal with more advanced topics, such
as interactive plots, regression models, and writing your own
functions. All sections are organized around examples, and most
contain some suggested exercises for the reader.
This document is not intended to be a complete manual. However,
documentation for many of the commands that are available is given in
the appendix. Brief help messages for these and other commands are also
available through the interactive help facility described in
Section 5.1 below.
Common Lisp (CL) is a dialect of the Lisp programming language,
published in ANSI standard document ANSI INCITS 226-1994 (S20018)
(formerly X3.226-1994 (R1999)). The Common Lisp language was
developed as a standardized and improved successor of Maclisp. By the
early 1980s several groups were already at work on diverse successors
to MacLisp: Lisp Machine Lisp (aka ZetaLisp), Spice Lisp, NIL and S-1
Lisp. Common Lisp sought to unify, standardize, and extend the
features of these MacLisp dialects. Common Lisp is not an
implementation, but rather a language specification. Several
implementations of the Common Lisp standard are available, including
free and open-source software and proprietary products. Common Lisp
is a general-purpose, multi-paradigm programming language. It
supports a combination of procedural, functional, and object-oriented
programming paradigms. As a dynamic programming language, it
facilitates evolutionary and incremental software development, with
iterative compilation into efficient run-time programs. This
incremental development is often done interactively without
interrupting the running application.
Using this Tutorial
The best way to learn about a new computer programming language is
usually to use it. You will get most out of this tutorial if you read
it at your computer and work through the examples yourself. To make
this tutorial easier the named data sets used in this tutorial have
been stored in the file basic.lisp in the LS:DATASETS;TUTORIALS
folder of the system. To load this file, execute:
(load #P"LS:DATASETS;TUTORIALS;basic")
at the command prompt (REPL). The file will be loaded and some
variables will be defined for you.
Why LISP-STAT Exists
There are three primary reasons behind the decision to produce the
LISP-STAT environment. The first is speed. The other major languages
used for statistics and numerical analysis, R, Python and Julia are
all fine languages, but with the rise of ‘big data’ and large data
sets, require workarounds for processing large data sets. Furthermore,
as interpreted languages, they are relatively slow when compared to
Common Lisp, that has a compiler that produces native machine code.
Not only does Common Lisp provide a compiler that produces machine
code, it has native threading, a rich ecosystem of code libraries, and
a history of industrial deployments, including:
Credit card authorization at AMEX (Authorizers Assistant)
US DoD logistics (and more, that we don’t know of)
CIA and NSA are big users based on Lisp sales
DWave and Rigetti use lisp for programming their quantum computers
Apple’s Siri was originally written in Lisp
Amazon got started with Lisp & C; so did Y-combinator
Google’s flight search engine is written in Common Lisp
AT&T used a stripped down version of Symbolics Lisp to process CDRs in the first IP switches
Python and R are never (to my knowledge) deployed as front-line
systems, but used in the back office to produce models that are
executed by other applications in enterprise environments. Common Lisp
eliminates that friction.
Availability
Source code for LISP-STAT is available in the Lisp-Stat github
repository. The Getting
Started section of the
documentation contains instructions for downloading and installing the
system.
Disclaimer
LISP-STAT is an experimental program. Although it is in daily use on
several projects, the corporate sponsor, Symbolics Pte Ltd, takes no
responsibility for losses or damages resulting directly or indirectly
from the use of this program.
LISP-STAT is an evolving system. Over time new features will be
introduced, and existing features that do not work may be changed.
Every effort will be made to keep LISP-STAT consistent with the
information in this tutorial, but if this is not possible the
reference documentation should give accurate
information about the current use of a command.
Starting and Finishing
Once you have obtained the source code or pre-built image, you can
load Lisp-Stat using QuickLisp. If
you do not have quicklisp, stop here and get it. It is the de-facto
package manager for Common Lisp and you will need it. This is what
you will see if loading using the
Slime IDE:
You may see more or less output, depending on whether dependent
packages have been compiled before. If this is your first time
running anything in this implementation of Common Lisp, you will
probably see output related to the compilation of every module in the
system. This could take a while, but only has to be done once.
Once completed, to use the functions provided, you need to make the
LISP-STAT package the current package, like this:
The final LS-USER> in the window is the Slime prompt. Notice how it
changes when you executed (in-package). In Slime, the prompt always
indicates the current package, *package*. Any characters you type
while the prompt is active will be added to the line after the final
prompt. When you press return, LISP-STAT will try to interpret what
you have typed and will print a response. For example, if you type a
1 and press return then LISP-STAT will respond by simply printing a
1 on the following line and then give you a new prompt:
LS-USER> 1
1
LS-USER>
If you type an expression like (+ 1 2), then LISP-STAT will
print the result of evaluating the expression and give you a new prompt:
LS-USER> (+ 1 2)
3
LS-USER>
As you have probably guessed, this expression means that the numbers 1
and 2 are to be added together. The next section will give more
details on how LISP-STAT expressions work. In this tutorial I will
sometimes show interactions with the program as I have done here: The
LS-USER> prompt will appear before lines you should type.
LISP-STAT will supply this prompt when it is ready; you should not
type it yourself. In later sections I will omit the new prompt
following the result in order to save space.
Now that you have seen how to start up LISP-STAT it is a good idea to
make sure you know how to get out. The exact command to exit depends
on the Common Lisp implementation you use. For SBCL, you can type the
expression
LS-USER> (exit)
In other implementations, the command is quit. One of these methods
should cause the program to exit and return you to the IDE. In Slime,
you can use the , short-cut and then type sayoonara.
The Basics
Before we can start to use LISP-STAT for statistical work we need to
learn a little about the kind of data LISP-STAT uses and about how the
LISP-STAT listener and evaluator work.
Data
LISP-STAT works with two kinds of data: simple data and compound
data. Simple data are numbers
1 ; an integer
-3.14 ; a floating point number
#C(0 1) ; a complex number (the imaginary unit)
logical values
T ; true
nil ; false
strings (always enclosed in double quotes)
"This is a string 1 2 3 4"
and symbols (used for naming things; see the following section)
x
x12
12x
this-is-a-symbol
Compound data are lists
(this is a list with 7 elements)
(+ 1 2 3)
(sqrt 2)
or vectors
#(this is a vector with 7 elements)
#(1 2 3)
Higher dimensional arrays are another form of compound data; they will
be discussed below in Section 9, “Arrays”.
All the examples given above can be typed directly into the command
window as they are shown here. The next subsection describes what
LISP-STAT will do with these expressions.
The Listener and the Evaluator
A session with LISP-STAT basically consists of a conversation between
you and the listener. The listener is the window into which you
type your commands. When it is ready to receive a command it gives
you a prompt. At the prompt you can type in an expression. You can
use the mouse or the backspace key to correct any mistakes you make
while typing in your expression. When the expression is complete and
you type a return the listener passes the expression on to the
evaluator. The evaluator evaluates the expression and returns the
result to the listener for printing.1 The evaluator is the heart of
the system.
The basic rule to remember in trying to understand how the evaluator
works is that everything is evaluated. Numbers and strings evaluate to
themselves:
LS-USER> 1
1
LS-USER> "Hello"
"Hello"
LS-USER>
Lists are more complicated. Suppose you type the list (+ 1 2 3)
at the listener. This list has four elements: the symbol +
followed by the numbers 1, 2 and 3. Here is what happens:
> (+ 1 2 3)
6
>
This list is evaluated as a function application. The first element
is a symbol representing a function, in this case the symbol +
representing the addition function. The remaining elements are the
arguments. Thus the list in the example above is interpreted to mean
“Apply the function + to the numbers 1, 2 and 3”.
Actually, the arguments to a function are always evaluated before the
function is applied. In the previous example the arguments are all
numbers and thus evaluate to themselves. On the other hand, consider
LS-USER> (+ (* 2 3) 4)
10
LS-USER>
The evaluator has to evaluate the first argument to the function
+ before it can apply the function.
Occasionally you may want to tell the evaluator not to evaluate
something. For example, suppose we wanted to get the evaluator to simply
return the list (+ 1 2) back to us, instead of evaluating it. To
do this we need to quote our list:
LS-USER> (quote (+ 1 2))
(+ 1 2)
LS-USER>
quote is not a function. It does not obey the rules of function
evaluation described above: Its argument is not evaluated. quote is
called a special form – special because it has special rules for
the treatment of its arguments. There are a few other special forms
that we will need; I will introduce them as they are needed. Together
with the basic evaluation rules described here these special forms
make up the basics of the Lisp language. The special form quote is
used so often that a shorthand notation has been developed, a single
quote before the expression you want to quote:
LS-USER> '(+ 1 2) ; single quote shorthand
This is equivalent to (quote (+ 1 2)). Note that there is no
matching quote following the expression.
By the way, the semicolon ; is the Lisp comment character.
Anything you type after a semicolon up to the next time you press
return is ignored by the evaluator.
Exercises
For each of the following expressions try to predict what the evaluator
will return. Then type them in, see what happens and try to explain any
differences.
(+ 3 5 6)
(+ (- 1 2) 3)
’(+ 3 5 6)
’( + (- 1 2) 3)
(+ (- (* 2 3) (/ 6 2)) 7)
’x
Remember, to quit from LISP-STAT type (exit), quit or use the
IDE’s exit mechanism.
Elementary Statistical Operations
This section introduces some of the basic graphical and numerical
statistical operations that are available in LISP-STAT.
First Steps
Statistical data usually consists of groups of numbers. Devore and Peck
[@DevorePeck Exercise 2.11] describe an experiment in which 22 consumers
reported the number of times they had purchased a product during the
previous 48 week period. The results are given as a table:
0 2 5 0 3 1 8 0 3 1 1
9 2 4 0 2 9 3 0 1 9 8
To examine this data in LISP-STAT we represent it as a list of numbers
using the list function:
The text boxes above have a ‘copy’ button if
you hover on them. For some examples, I will give the commands alone in
the text box so that you can copy & paste the code into the REPL
Note that the numbers are separated by white space (spaces, tabs or even
returns), not commas.
The mean function can be used to compute the average of a list of
numbers. We can combine it with the list function to find the
average number of purchases for our sample:
It is of course a nuisance to have to type in the list of 22 numbers
every time we want to compute a statistic for the sample. To avoid
having to do this I will give this list a name using the def
special form 2:
Now the symbol purchases has a value associated with it: Its
value is our list of 22 numbers. If you give the symbol purchases
to the evaluator then it will find the value of this symbol and return
that value:
Common Lisp provides two functions to define
variables defparameter and defvar. Variables defined with
defparameter can be modified without a warning. If you attempt to
modify a variable defined with defvar a warning will be issued and
you will have to confirm the change.
We can now easily compute various numerical descriptive statistics for
this data set:
LISP-STAT also supports elementwise arithmetic operations on vectors
of numbers. Technically, overriding, or ‘shadowing’ any of the Common
Lisp functions is undefined. This is usually an euphuism for
‘something really bad will happen’, so the vector functions are
located in the package elmt and prefixed by e to distinguish them
from the Common Lisp variants, e.g. e+ for addition, e* for
multiplication, etc. Presently these functions work only on vectors,
so we’ll define a new purchases variable as a vector type:
Using the e prefix for mathematical
operators is a temporary situation. We know how to merge vectorized
mathematics into the base Common Lisp, but since we have a functioning
system, this work is lower priority. Volunteers to take this on are
welcome.
Exercises
For each of the following expressions try to predict what the evaluator
will return. Then type them in, see what happens and try to explain any
differences.
(mean (list 1 2 3))
(e+ #(1 2 3) 4)
(e* #(1 2 3) #(4 5 6))
(e+ #(1 2 3) #(4 5 7))
Summary Statistics
Devore and Peck [@DevorePeck page 54, Table 10] give precipitation
levels recorded during the month of March in the Minneapolis - St. Paul
area over a 30 year period. Let’s enter these data into LISP-STAT with
the name precipitation:
In typing the expression above I have inserted return and tab a
few times in order to make the typed expression easier to read. The
tab key indents the next line to a reasonable point to make the
expression more readable.
The distribution of this data set is somewhat skewed to the right.
Notice the separation between the mean and the median. You might want
to try a few simple transformations to see if you can symmetrize the
data. Square root and log transformations can be computed using the
expressions
(esqrt precipitation)
and
(elog precipitation)
You should look at plots of the data to see if these transformations do
indeed lead to a more symmetric shape. The means and medians of the
transformed data are:
This section briefly summarizes some techniques for generating random
and systematic data.
Generating Random Data
The state of the internal random number generator can be “randomly”
reseeded, and the current value of the generator state can be saved. The
mechanism used is the standard Common Lisp mechanism. The current random
state is held in the variable *random-state*. The function
make-random-state can be used to set and save the state. It takes
an optional argument. If the argument is NIL or omitted
make-random-state returns a copy of the current value of
*random-state*. If the argument is a state object, a copy of it is
returned. If the argument is t a new, “randomly” initialized
state object is produced and returned. 3
Forming Subsets and Deleting Cases
The select function allows you to select a single element or a
group of elements from a list or vector. For example, if we define
x by
(def x (list 3 7 5 9 12 3 14 2))
then (select x i) will return the ith element of x.
Common Lisp, like the language C, but in contrast to FORTRAN, numbers
elements of list and vectors starting at zero. Thus the indices for
the elements of x are 0, 1, 2, 3, 4, 5, 6, 7 . So
LS-USER> (select x 0)
3
LS-USER> (select x 2)
5
To get a group of elements at once we can use a list of indices instead
of a single index:
LS-USER> (select x (list 0 2))
(3 5)
If you want to select all elements of x except element 2 you can
use the expression
At times you may want to combine several short lists or vectors into a
single longer one. This can be done using the append function. For
example, if you have three variables x, y and z constructed by
the expressions
(def x (list 1 2 3))
(def y (list 4))
(def z (list 5 6 7 8))
then the expression
(append x y z)
will return the list
(1 2 3 4 5 6 7 8).
For vectors, we use the more general function concatenate, which
operates on sequences, that is objects of either list or vector:
Notice that we had to indicate the return type, using the 'vector
argument to concatenate. We could also have said 'list to have it
return a list, and it would have coerced the arguments to the correct
type.
Modifying Data
So far when I have asked you to type in a list of numbers I have been
assuming that you will type the list correctly. If you made an error
you had to retype the entire def expression. Since you can use
cut & paste this is really not too serious. However it would be
nice to be able to replace the values in a list after you have typed
it in. The setf special form is used for this. Suppose you would
like to change the 12 in the list x used in the Section
4.3 to 11. The expression
(setf (select x 4) 11)
will make this replacement:
LS-USER> (setf (select x 4) 11)
11
LS-USER> x
(3 7 5 9 11 3 14 2)
The general form of setf is
(setf form value)
where form is the expression you would use to select a single
element or a group of elements from x and value is the
value you would like that element to have, or the list of the values for
the elements in the group. Thus the expression
(setf (select x (list 0 2)) (list 15 16))
changes the values of elements 0 and 2 to 15 and 16:
Lisp symbols are merely labels for
different items. When you assign a name to an item with the defvar or defparameter
commands you are not producing a new item. Thus
(defparameter x (list 1 2 3 4))
(defparameter y x)
means that x and y are two different names for the same
thing.
As a result, if we change an element of (the item referred to by) x
with setf then we are also changing the element of (the item
referred to by) y, since both x and y refer to the same item. If
you want to make a copy of x and store it in y before you make
changes to x then you must do so explicitly using, say, the
copy-list function. The
expression
(defparameter y (copy-list x))
will make a copy of x and set the value of y to that copy.
Now x and y refer to different items and changes to
x will not affect y.
Useful Shortcuts
This section describes some additional features of LISP-STAT that you
may find useful.
Getting Help
On line help is available for many of the functions in LISP-STAT 4.
As an example, here is how you would get help for the function
iota:
LS-USER> (documentation 'iota 'function)
"Return a list of n numbers, starting from START (with numeric contagion
from STEP applied), each consecutive number being the sum of the previous one
and STEP. START defaults to 0 and STEP to 1.
Examples:
(iota 4) => (0 1 2 3)
(iota 3 :start 1 :step 1.0) => (1.0 2.0 3.0)
(iota 3 :start -1 :step -1/2) => (-1 -3/2 -2)
"
Note the quote in front of iota. documentation is itself a
function, and its argument is the symbol representing the function
iota. To make sure documentation receives the symbol, not the
value of the symbol, you need to quote the symbol.
Another useful function is describe that, depending on the Lisp
implementation, will return documentation and additional information
about the object:
LS-USER> (describe 'iota)
ALEXANDRIA:IOTA
[symbol]
IOTA names a compiled function:
Lambda-list: (ALEXANDRIA::N &KEY (ALEXANDRIA::START 0) (STEP 1))
Derived type: (FUNCTION
(UNSIGNED-BYTE &KEY (:START NUMBER) (:STEP NUMBER))
(VALUES T &OPTIONAL))
Documentation:
Return a list of n numbers, starting from START (with numeric contagion
from STEP applied), each consecutive number being the sum of the previous one
and STEP. START defaults to 0 and STEP to 1.
Examples:
(iota 4) => (0 1 2 3)
(iota 3 :start 1 :step 1.0) => (1.0 2.0 3.0)
(iota 3 :start -1 :step -1/2) => (-1 -3/2 -2)
Inline proclamation: INLINE (inline expansion available)
Source file: s:/src/third-party/alexandria/alexandria-1/numbers.lisp
Note
Generally describe is better to use than documentation. The ANSI Common Lisp spec
has this to say about documentation:
“Documentation strings are made available for debugging purposes. Conforming programs are permitted to use documentation strings when they are present, but should not depend for their correct behavior on the presence of those documentation strings. An implementation is permitted to discard documentation strings at any time for implementation-defined reasons.”
If you are not sure about the name of a function you may still be able
to get some help. Suppose you want to find out about functions related
to the normal distribution. Most such functions will have “norm” as part
of their name. The expression
(apropos 'norm)
will print the help information for all symbols whose names contain the
string “norm”:
Let me briefly explain the notation used in the information printed by
describe regarding the arguments a function expects 5. This is
called the lambda-list. Most functions expect a fixed set of
arguments, described in the help message by a line like Args: (x y z) or Lambda-list: (x y z)
Some functions can take one or more optional arguments. The arguments
for such a function might be listed as
Args: (x &optional y (z t))
or
Lambda-list: (x &optional y (z t))
This means that x is required and y and z are
optional. If the function is named f, it can be called as
(f x-val), (f x-val y-val) or
(f x-val y-val z-val). The list (z t) means that if
z is not supplied its default value is T. No explicit
default value is specified for y; its default value is therefore
NIL. The arguments must be supplied in the order in which they
are listed. Thus if you want to give the argument z you must also
give a value for y.
Another form of optional argument is the keyword argument. The
iota function for example takes arguments
Args: (N &key (START 0) (STEP 1))
The n argument is required, the START argument is an optional
keyword argument. The default START is 0, and the default STEP
is 1. If you want to create a sequence eight numbers, with a step of
two) use the expression
(iota 8 :step 2)
Thus to give a value for a keyword argument you give the keyword 6
for the argument, a symbol consisting of a colon followed by the
argument name, and then the value for the argument. If a function can
take several keyword arguments then these may be specified in any order,
following the required and optional arguments.
Finally, some functions can take an arbitrary number of arguments. This
is denoted by a line like
Args: (x &rest args)
The argument x is required, and zero or more additional arguments
can be supplied.
In addition to providing information about functions describe also
gives information about data types and certain variables. For example,
LS-USER> (describe 'complex)
COMMON-LISP:COMPLEX
[symbol]
COMPLEX names a compiled function:
Lambda-list: (REALPART &OPTIONAL (IMAGPART 0))
Declared type: (FUNCTION (REAL &OPTIONAL REAL)
(VALUES NUMBER &OPTIONAL))
Derived type: (FUNCTION (T &OPTIONAL T)
(VALUES
(OR RATIONAL (COMPLEX SINGLE-FLOAT)
(COMPLEX DOUBLE-FLOAT) (COMPLEX RATIONAL))
&OPTIONAL))
Documentation:
Return a complex number with the specified real and imaginary components.
Known attributes: foldable, flushable, unsafely-flushable, movable
Source file: SYS:SRC;CODE;NUMBERS.LISP
COMPLEX names the built-in-class #<BUILT-IN-CLASS COMMON-LISP:COMPLEX>:
Class precedence-list: COMPLEX, NUMBER, T
Direct superclasses: NUMBER
Direct subclasses: SB-KERNEL:COMPLEX-SINGLE-FLOAT,
SB-KERNEL:COMPLEX-DOUBLE-FLOAT
Sealed.
No direct slots.
COMPLEX names a primitive type-specifier:
Lambda-list: (&OPTIONAL (SB-KERNEL::TYPESPEC '*))
shows the function, type and class documentation for complex, and
LS-USER> (documentation 'pi 'variable)
PI [variable-doc]
The floating-point number that is approximately equal to the ratio of the
circumference of a circle to its diameter.
After you have been working for a while you may want to find out what
variables you have defined (using def). The function
variables will produce a listing:
LS-USER> (variables)
CO
HC
RURAL
URBAN
PRECIPITATION
PURCHASES
NIL
LS-USER>
If you are working with very large variables you may occasionally want
to free up some space by getting rid of some variables you no longer
need. You can do this using the undef-var function:
LS-USER> (undef-var 'co)
CO
LS-USER> (variables)
HC
RURAL
URBAN
PRECIPITATION
PURCHASES
NIL
LS-USER>
More on the Listener
Common Lisp provides a simple command history mechanism. The symbols
-, ``, *, **, +, ++, and +++ are used for this purpose. The
top level reader binds these symbols as follows:
`-` the current input expression
`+` the last expression read
`++` the previous value of `+`
`+++` the previous value of `++`
`` the result of the last evaluation
`*` the previous value of ``
`**` the previous value of `*`
The variables ``, * and ** are probably most useful.
For example, if you read a data-frame but forget to assign the
resulting object to a variable:
LS-USER> (read-csv rdata:mtcars)
WARNING: Missing column name was filled in
#<DATA-FRAME (32 observations of 12 variables)>
you can recover it using one of the history variables:
(defparameter mtcars *)
; MTCARS
The symbol MTCARS now has the data-frame object as its value.
Like most interactive systems, Common Lisp needs a system for
dynamically managing memory. The system used depends on the
implementation. The most common way (SBCL, CCL) is to grab memory out
of a fixed bin until the bin is exhausted. At that point the system
pauses to reclaim memory that is no longer being used. This process,
called garbage collection, will occasionally cause the system to
pause if you are using large amounts of memory.
Loading Files
The data for the examples and exercises in this tutorial, when not
loaded from the network, have been stored on files with names ending
in .lisp. In the LISP-STAT system directory they can be found in the
folder Datasets. Any variables you save (see the next subsection for
details) will also be saved in files of this form. The data in these
files can be read into LISP-STAT with the load function. To load a
file named randu.lisp type the expression
(load #P"LS:DATASETS;RANDU.LISP")
or just
(load #P"LS:DATASETS;randu")
If you give load a name that does not end in .lisp then
load will add this suffix.
Saving Your Work
Save a Session
If you want to record a session with LISP-STAT you can do so using the
dribble function. The expression
(dribble "myfile")
starts a recording. All expressions typed by you and all results
printed by LISP-STAT will be entered into the file named myfile.
The expression
(dribble)
stops the recording. Note that (dribble "myfile") starts a new
file by the name myfile. If you already have a file by that name
its contents will be lost. Thus you can’t use dribble to toggle on and
off recording to a single file.
dribble only records text that is typed, not plots. However, you
can use the buttons displayed on a plot to save in SVG or PNG format.
The original HTML plots are saved in your operating system’s TEMP
directory and can be viewed again until the directory is cleared
during a system reboot.
Saving Variables
Variables you define in LISP-STAT only exist for the duration of the
current session. If you quit from LISP-STAT your data will be lost.
To preserve your data you can use the savevar function. This
function allows you to save one a variable into a file. Again
a new file is created and any existing file by the same name is
destroyed. To save the variable precipitation in a file called
precipitation type
(savevar 'precipitation "precipitation")
Do not add the .lisp suffix yourself; save will supply
it. To save the two variables precipitation and purchases
in the file examples.lisp type 8.
(savevar '(purchases precipitation) "examples")
The files precipitation.lisp and examples.lisp now contain a set
of expression that, when read in with the load command, will
recreate the variables precipitation and purchases. You can look
at these files with an editor like the Emacs editor and you can
prepare files with your own data by following these examples.
Reading Data Files
The data files we have used so far in this tutorial have contained
Common Lisp expressions. LISP-STAT also provides functions for
reading raw data files. The most commonly used is read-csv.
(read-csv stream)
where stream is a Common Lisp stream with the data. Streams can be
obtained from files, strings or a network and are in comma separated
value (CSV) format. The parser supports delimiters other than comma.
The character delimited reader should be adequate for most purposes.
If you have to read a file that is not in a character delimited format
you can use the raw file handling functions of Common Lisp.
User Initialization File
Each Common Lisp implementation provides a way to execute
initialization code upon start-up. You can use this file to load any
data sets you would like to have available or to define functions of
your own.
LISP-STAT also has an initialization file, ls-init.lisp, in your
home directory. Typically you will use the lisp implementation
initialization file for global level initialization, and
ls-init.lisp for data related customizations. See the section
Initialization
file in the
manual for more information.
Defining Functions & Methods
This section gives a brief introduction to programming LISP-STAT. The
most basic programming operation is to define a new function. Closely
related is the idea of defining a new method for an object. 9
Defining Functions
You can use the Common Lisp language to define functions of your
own. Many of the functions you have been using so far are written in
this language. The special form used for defining functions is called
defun. The simplest form of the defun syntax is
(defun fun args expression)
where fun is the symbol you want to use as the function name, args
is the list of the symbols you want to use as arguments, and
expression is the body of the function. Suppose for example that
you want to define a function to delete a case from a list. This
function should take as its arguments the list and the index of the
case you want to delete. The body of the function can be based on
either of the two approaches described in Section
4.3 above. Here is one approach:
(defun delete-case (x i)
(select x (remove i (iota (- (length x) 1)))))
I have used the function length in this definition to determine
the length of the argument x. Note that none of the arguments to
defun are quoted: defun is a special form that does not
evaluate its arguments.
Unless the functions you define are very simple you will probably want
to define them in a file and load the file into LISP-STAT with the
load command. You can put the functions in the implementation’s initialization
file or include in the initialization file a load
command that will load another file. The version of Common Lisp for the
Macintosh, CCL, includes a simple editor that can be used from within
LISP-STAT.
Matrices and Arrays
LISP-STAT includes support for multidimensional arrays. In addition to
the standard Common Lisp array functions, LISP-STAT also includes a
system called
array-operations.
An array is printed using the standard Common Lisp format. For example,
a 2 by 3 matrix with rows (1 2 3) and (4 5 6) is printed as
#2A((1 2 3)(4 5 6))
The prefix #2A indicates that this is a two-dimensional array. This
form is not particularly readable, but it has the advantage that it can
be pasted into expressions and will be read as an array by the LISP
reader.10 For matrices you can use the function print-matrix
to get a slightly more readable representation:
The select function can be used to extract elements or sub-arrays
from an array. If A is a two dimensional array then the
expression
(select a 0 1)
will return element 1 of row 0 of A. The expression
(select a (list 0 1) (list 0 1))
returns the upper left hand corner of A.
References
Bates, D. M. and Watts, D. G., (1988), Nonlinear Regression Analysis
and its Applications, New York: Wiley.
Becker, Richard A., and Chambers, John M., (1984), S: An Interactive
Environment for Data Analysis and Graphics, Belmont, Ca: Wadsworth.
Becker, Richard A., Chambers, John M., and Wilks, Allan R., (1988), The
New S Language: A Programming Environment for Data Analysis and
Graphics, Pacific Grove, Ca: Wadsworth.
Becker, Richard A., and William S. Cleveland, (1987), “Brushing
scatterplots,” Technometrics, vol. 29, pp. 127-142.
Betz, David, (1988), “XLISP: An experimental object-oriented programming
language,” Reference manual for XLISP Version 2.0.
Chaloner, Kathryn, and Brant, Rollin, (1988) “A Bayesian approach to
outlier detection and residual analysis,” Biometrika, vol. 75, pp.
651-660.
Cleveland, W. S. and McGill, M. E., (1988) Dynamic Graphics for
Statistics, Belmont, Ca.: Wadsworth.
Cox, D. R. and Snell, E. J., (1981) Applied Statistics: Principles and
Examples, London: Chapman and Hall.
Dennis, J. E. and Schnabel, R. B., (1983), Numerical Methods for
Unconstrained Optimization and Nonlinear Equations, Englewood Cliffs,
N.J.: Prentice-Hall.
Devore, J. and Peck, R., (1986), Statistics, the Exploration and
Analysis of Data, St. Paul, Mn: West Publishing Co.
McDonald, J. A., (1982), “Interactive Graphics for Data Analysis,”
unpublished Ph. D. thesis, Department of Statistics, Stanford
University.
Oehlert, Gary W., (1987), “MacAnova User’s Guide,” Technical Report 493,
School of Statistics, University of Minnesota.
Press, Flannery, Teukolsky and Vetterling, (1988), Numerical Recipes in
C, Cambridge: Cambridge University Press.
Steele, Guy L., (1984), Common Lisp: The Language, Bedford, MA:
Digital Press.
Stuetzle, W., (1987), “Plot windows,” J. Amer. Statist. Assoc., vol.
82, pp. 466 - 475.
Tierney, Luke, (1990) LISP-STAT: Statistical Computing and Dynamic
Graphics in Lisp. Forthcoming.
Tierney, L. and J. B. Kadane, (1986), “Accurate approximations for
posterior moments and marginal densities,” J. Amer. Statist. Assoc.,
vol. 81, pp. 82-86.
Tierney, Luke, Robert E. Kass, and Joseph B. Kadane, (1989), “Fully
exponential Laplace approximations to expectations and variances of
nonpositive functions,” J. Amer. Statist. Assoc., to appear.
Tierney, L., Kass, R. E., and Kadane, J. B., (1989), “Approximate
marginal densities for nonlinear functions,” Biometrika, to appear.
Weisberg, Sanford, (1982), “MULTREG Users Manual,” Technical Report 298,
School of Statistics, University of Minnesota.
Winston, Patrick H. and Berthold K. P. Horn, (1988), LISP, 3rd Ed.,
New York: Addison-Wesley.
Appendix A: LISP-STAT Interface to the Operating System
A.1 Running System Commands from LISP-STAT
The run-program function can be used to run UNIX commands from within
LISP-STAT. This function takes a shell command string as its argument
and returns the shell exit code for the command. For example, you can
print the date using the UNIX date command:
The return value is 0, indicating successful completion of the UNIX
command.
It is possible to make a finer distinction. The reader takes a
string of characters from the listener and converts it into an
expression. The evaluator evaluates the expression and the
printer converts the result into another string of characters for
the listener to print. For simplicity I will use evaluator to
describe the combination of these functions. ↩︎
def acts like a special form, rather than a function, since
its first argument is not evaluated (otherwise you would have to
quote the symbol). Technically def is a macro, not a special
form, but I will not worry about the distinction in this tutorial.
def is closely related to the standard Lisp special forms
setf and setq. The advantage of using def is
that it adds your variable name to a list of def‘ed variables
that you can retrieve using the function variables. If you
use setf or setq there is no easy way to find
variables you have defined, as opposed to ones that are predefined.
def always affects top level symbol bindings, not local
bindings. It cannot be used in function definitions to change local
bindings. ↩︎
The generator used is Marsaglia’s portable generator from the
Core Math Libraries distributed by the National Bureau of
Standards. A state object is a vector containing the state
information of the generator. “Random” reseeding occurs off the
system clock. ↩︎
The notation used corresponds to the specification of the
argument lists in Lisp function definitions. See Section
8{reference-type=“ref” reference=“Fundefs”} for more
information on defining functions. ↩︎
Note that the keyword :title has not been quoted. Keyword
symbols, symbols starting with a colon, are somewhat special. When
a keyword symbol is created its value is set to itself. Thus a
keyword symbol effectively evaluates to itself and does not need to
be quoted. ↩︎
Actually pi represents a constant, produced with
defconst. Its value cannot be changed by simple assignment. ↩︎
I have used a quoted list ’(purchases precipitation) in
this expression to pass the list of symbols to the savevar
function. A longer alternative would be the expression
(list ’purchases ’precipitation).↩︎
The discussion in this section only scratches the surface of what
you can do with functions in the XLISP language. To see more
examples you can look at the files that are loaded when XLISP-STAT
starts up. For more information on options of function definition,
macros, etc. see the XLISP documentation and the books on Lisp
mentioned in the references. ↩︎
You should quote an array if you type it in using this form, as
the value of an array is not defined. ↩︎
(data :mtcars-example)
;; WARNING: Missing column name was filled in
;; T
Examine data
Lisp-Stat’s printing system is integrated with the Common Lisp Pretty
Printing
facility. To control aspects of printing, you can use the built in
lisp pretty printing configuration system. By default Lisp-Stat sets
*print-pretty* to nil.
Basic information
Type the name of the data frame at the REPL to get a simple one-line
summary.
mtcars
;; #<DATA-FRAME MTCARS (32 observations of 12 variables)
;; Motor Trend Car Road Tests>
Printing data
By default, the head function will print the first 6 rows:
The two dots “..” at the end indicate that output has been truncated.
Lisp-Stat sets the default for pretty printer *print-lines* to 25
rows and output more than this is truncated. If you’d like to print
all rows, set this value to nil, (setf *print-lines* nil)
Notice the column named X1. This is the name given to the column by
the data reading function. Note the warning that was issued during the
import. Missing columns are named X1, X2, …, Xn in increasing order
for the duration of the Lisp-Stat session.
This column is actually the row name, so we’ll rename it:
(rename! mtcars 'model 'x1)
The keys of a data frame are symbols, so you need to quote them to
prevent the reader from trying to evaluate them to a value.
Note that your row may be named something other than X1, depending
on whether or not you have loaded any other data frames with variable
name replacement. Also note: the ! at the end of the function
name. This is a convention indicating a destructive operation; a copy
will not be returned, it’s the actual data that will be modified.
Remember we mentioned that the keys (column names) are symbols?
Compare the above to the keys of the data frame:
(keys mtcars)
;; => #(MODEL MPG CYL DISP HP DRAT WT QSEC VS AM GEAR CARB)
These symbols are printed without double quotes. If a function takes
a key, it must be quoted, e.g. 'mpg and not mpg or "mpg"
Dimensions
We saw the dimensions above in basic information. That was a printed
for human consumption. To get the values in a form suitable for
passing to other functions, use the dims command:
(aops:dims mtcars) ;; => (32 12)
Common Lisp specifies dimensions in row-column order, so mtcars has
32 rows and 12 columns.
Note
Lisp-Stat generally follows the tidyverse philosophy when it comes to row names. By definition, row names are unique, so there is no point including them in a statistical analysis. Nevertheless, many data sets include row names, so we include some special handling for columns with all distinct values; they are excluded by default from summaries (and you can include it if you wish). There is no concept of independent row names as with a R data frame. A Lisp-Stat data frame is more like a tibble.
Basic Statistics
Minimum & Maximum
To get the minimum or maximum of a column, say mpg, you can use several
Common Lisp methods. Let’s see what mpg looks like by typing
the name of the column into the REPL:
LS-USER> (summary mtcars)
(
MPG (Miles/(US) gallon)
n: 32
missing: 0
min=10.40
q25=15.40
q50=19.20
mean=20.09
q75=22.80
max=33.90
CYL (Number of cylinders)
14 (44%) x 8, 11 (34%) x 4, 7 (22%) x 6,
DISP (Displacement (cu.in.))
n: 32
missing: 0
min=71.10
q25=120.65
q50=205.87
mean=230.72
q75=334.00
max=472.00
HP (Gross horsepower)
n: 32
missing: 0
min=52
q25=96.00
q50=123
mean=146.69
q75=186.25
max=335
DRAT (Rear axle ratio)
n: 32
missing: 0
min=2.76
q25=3.08
q50=3.70
mean=3.60
q75=3.95
max=4.93
WT (Weight (1000 lbs))
n: 32
missing: 0
min=1.51
q25=2.54
q50=3.33
mean=3.22
q75=3.68
max=5.42
QSEC (1/4 mile time)
n: 32
missing: 0
min=14.50
q25=16.88
q50=17.71
mean=17.85
q75=18.90
max=22.90
VS (Engine (0=v-shaped, 1=straight))
ones: 14 (44%)
AM (Transmission (0=automatic, 1=manual))
ones: 13 (41%)
GEAR (Number of forward gears)
15 (47%) x 3, 12 (38%) x 4, 5 (16%) x 5,
CARB (Number of carburetors)
10 (31%) x 4, 10 (31%) x 2, 7 (22%) x 1, 3 (9%) x 3, 1 (3%) x 6, 1 (3%) x 8, )
Recall that the column named model is treated specially, notice
that it is not included in the summary. You can see why it’s excluded
by examining the column’s summary:
LS-USER>(pprint (summarize-column 'mtcars:model)))
1 (3%) x "Mazda RX4", 1 (3%) x "Mazda RX4 Wag", 1 (3%) x "Datsun 710", 1 (3%) x "Hornet 4 Drive", 1 (3%) x "Hornet Sportabout", 1 (3%) x "Valiant", 1 (3%) x "Duster 360", 1 (3%) x "Merc 240D", 1 (3%) x "Merc 230", 1 (3%) x "Merc 280", 1 (3%) x "Merc 280C", 1 (3%) x "Merc 450SE", 1 (3%) x "Merc 450SL", 1 (3%) x "Merc 450SLC", 1 (3%) x "Cadillac Fleetwood", 1 (3%) x "Lincoln Continental", 1 (3%) x "Chrysler Imperial", 1 (3%) x "Fiat 128", 1 (3%) x "Honda Civic", 1 (3%) x "Toyota Corolla", 1 (3%) x "Toyota Corona", 1 (3%) x "Dodge Challenger", 1 (3%) x "AMC Javelin", 1 (3%) x "Camaro Z28", 1 (3%) x "Pontiac Firebird", 1 (3%) x "Fiat X1-9", 1 (3%) x "Porsche 914-2", 1 (3%) x "Lotus Europa", 1 (3%) x "Ford Pantera L", 1 (3%) x "Ferrari Dino", 1 (3%) x "Maserati Bora", 1 (3%) x "Volvo 142E",
Columns with unique values in each row aren’t very interesting.
Saving data
To save a data frame to a CSV file, use the write-csv
method. Here we save mtcars into the Lisp-Stat datasets directory,
including the column names:
The plot system provides a way to generate specifications for
plotting applications. Examples of plotting packages include
gnuplot, plotly and
vega/vega-lite.
Plot includes a back end for Vega-Lite; this tutorial will teach you
how to encode Vega-Lite plot specifications using Common Lisp. For
help on Vega-Lite, see the Vega-Lite
tutorials.
For the most part, you can transcribe a Vega-Lite specification
directly into Common Lisp and adapt it for your own plots.
Preliminaries
Load Vega-Lite
Load Vega-Lite and network libraries:
(asdf:load-system :plot/vega)
and change to the Lisp-Stat user package:
(in-package :ls-user)
Load example data
The examples in this section use the vega-lite data sets. Load them all now:
(vega:load-vega-examples)
Note
If you get an error related to cl-date-time-parser or chroncity (only seen on Allegro Common Lisp), then load them manually with (ql:quickload :cl-date-time-parser) and (ql:quickload :chronicity) and re-run (vega:load-vega-examples)
Anatomy of a spec
Plot takes advantage of the fact that Vega-Lite’s JSON specification
is very close to that of a plist. If you are familiar with Common
Lisp’s ASDF system, then you will be familiar with plot’s way of
specifying graphics (plot was modeled on ASDF).
{
"$schema": "https://vega.github.io/schema/vega-lite/v5.json",
"description": "A scatterplot showing horsepower and miles per gallons for various cars.",
"data": {"url": "data/cars.json"},
"mark": "point",
"encoding": {
"x": {"field": "Horsepower", "type": "quantitative"},
"y": {"field": "Miles_per_Gallon", "type": "quantitative"}
}
}
and compare it with the equivalent Lisp-Stat version:
(plot:plot
(vega:defplot hp-mpg
`(:title "Vega Cars Horsepower vs. MPG"
:description "Horsepower vs miles per gallon for various cars"
:data (:values ,vgcars)
:mark :point
:encoding (:x (:field :horsepower :type :quantitative)
:y (:field :miles-per-gallon :type :quantitative)))))
Note that in the Lisp-Stat version we are embedding the data
using the :values keyword, as opposed to obtaining it from a server
with :url. You can try plotting this now: click on the copy button
in the upper right corner of the code box and paste it into the REPL.
You should see a window open with the plot displayed:
Your first plot
Data sources
The data property
tells Vega where the data for the plot is. Most, but not all,
specifications have a single, top level data property, e.g.
"data": {"url": "data/cars.json"}
Lisp-Stat allows you to use a data-frame, or data-frame
transformation (filter, selection, etc) as the value for the
data property. For example, since a data-frame transformation
returns a data-frame, we can insert the results as the data value,
as in this plot of residuals:
where we remove :NA and any release-date after 2018.
Vega has
transformations
as well, but are a bit clumsy compared to those in Lisp-Stat.
Sometimes though, you’ll need them because a particular transformation
is not something you want to do to your data-frame. You can mix
transformations in a single plot, as we saw above in the residuals
plot, where the filtering was done in your data-frame and the
transformation was done in vega-lite.
Below are several examples of the hp-mpg plot, using various data sources:
Embedded
Most of the examples in this documentation use embedded data, where the data is a part of the plot specification. For completeness sake, we repeat an example here:
(plot:plot
(vega:defplot hp-mpg
`(:title "Vega Cars Horsepower vs. MPG"
:description "Horsepower vs miles per gallon for various cars"
:data (:values ,vgcars)
:mark :point
:encoding (:x (:field :horsepower :type :quantitative)
:y (:field :miles-per-gallon :type :quantitative)))))
URL
Note in this example we do not use a data frame as a source, therefore we have to specify field encodings as strings, since variable names will not have been converted to idiomatic lisp. E.g. Miles_per_Gallon vs miles-per-gallon.
(plot:plot
(vega:defplot hp-mpg
`(:title "Horsepower vs. MPG"
:description "Horsepower vs miles per gallon for various cars"
:data (:url "https://raw.githubusercontent.com/vega/vega-datasets/next/data/cars.json")
:mark :point
:encoding (:x (:field "Horsepower" :type :quantitative)
:y (:field "Miles_per_Gallon" :type :quantitative)))))
In a production environment, you may have several quri data sources in your image. To load from one of these:
(plot:plot
(vega:defplot hp-mpg
`(:title "Horsepower vs. MPG"
:description "Horsepower vs miles per gallon for various cars"
:data (:url ,(quri:uri "https://raw.githubusercontent.com/vega/vega-datasets/next/data/cars.json"))
:mark :point
:encoding (:x (:field "Horsepower" :type :quantitative)
:y (:field "Miles_per_Gallon" :type :quantitative)))))
Here we create the quri object at the same time, since it’s a stand-alone example. It would probably already be created in an actual use case.
Named data
Vega has named data sources that are useful if you have to refer to the same data in several places. We can create one like this:
(plot:plot
(vega:defplot hp-mpg
`(:title "Horsepower vs. MPG"
:description "Horsepower vs miles per gallon for various cars"
:datasets (:my-data ,vgcars)
:data (:name :my-data)
:mark :point
:encoding (:x (:field :horsepower :type :quantitative)
:y (:field :miles-per-gallon :type :quantitative)))))
Plot specifications
Lisp in a spec
A plot specification is a plist. A nested plist to be exact
(or, perhaps more correctly, a tree). This means that we can use
Common Lisp tree/list functions to manipulate it.
If you look carefully at the examples, you’ll note they use a
backquote
(`) instead of a normal list quote ('). This is the mechanism
that Common Lisp
macros use to
rewrite code before compilation, and we can use the same mechanism to
rewrite our Vega-Lite specifications before encoding them.
The simplest, and most common, feature is insertion, like we did
above. By placing a comma (,) before the name of the data frame, we
told the backquote system to insert the value of the data frame
instead of the symbol (vgcars) in the example.
There’s a lot more you can do with the backquote mechanism. We won’t
say any more here, as it’s mostly a topic for advanced users. It’s
important for you to know it’s there though.
Properties
properties are the keys in key/value pairs. This is true whether
discussing a plist or JSON specification. Vega-Lite is case
sensitive and Common Lisp is not, so there are a few rules you need to
be aware of when constructing plot specifications.
Keys vs. values
Plot uses yason to transform a
plist plot specification to JSON. When yason encodes a spec
there are two functions of importance:
*symbol-encoder*
*symbol-key-encoder*
The former encodes values, and the latter encodes keys. In
PLOT, both of these are bound to a custom function
encode-symbol-as-metadata. This function does more than just encode
meta data though, it also handles naming conventions.
This won’t mean much in your day-to-day use of the system, but you do
need to be aware of the difference between encoding a key and a value.
There are some values that the encoder can’t work with, and in those
cases you’ll need to use text.
Finally, remember that the symbol encoders are just a convenience to
make things more lisp-like. You can build a plot specification, both
keys and values, entirely from text if you wish.
Encoding symbols
JavaScript identifiers are incompatible with Common Lisp identifiers,
so we need a way to translate between them. plot uses Parenscript
symbol
conversion
for this. This is one of the reasons for specialised symbol encoders.
Let’s look at the difference between the standard yason encoder and
the one provided by plot (Parenscript):
That difference is significant to Vega-Lite, where identifiers with a
- are not allowed. Vega is also case sensitive, so if a key is
xOffset, xoffset will not work. Fortunately Parenscript’s symbol
conversion is just what we need. It will automatically capitalise the
words following a dash, so x-offset becomes xOffset.
Symbols can also be used for value fields, and these are more
forgiving. As long as you are consistent, and keep in mind that a
behind the scenes conversion is happening, you can use lisp-like
identifiers. Where this mostly comes into play is when you are using
Vega transforms, as in the residuals example:
Notice that we used :imdb-rating as the field name for the
joinaggregate, however in the calculate part of the transform we
used the converted name imdbRating; that’s because by the time the
transform is run, the conversion will have already happened. When we
use :as we are assigning a name, when we use datum, we are
telling Vega to find a name, and since this is done in a text
field, plot won’t convert the names it finds inside text strings.
Finally, remember that the Parenscript transformation is also run on
variable/column names. You can see that we referred to imdb-rating
in the filter. If you get confused, run (keys <data-frame>) and
think about how ps:symbol-to-js-string would return the keys.
That’s what Vega will use as the column names.
This is more complicated to explain than to use. See the
examples for best practice patterns.
You’ll probably only need to be aware of this when doing transforms in
Vega.
Variable symbols
When you define a data frame using the defdf macro, Lisp-Stat sets
up an environment for that data set. Part of that environment
includes configuring a package with a symbol for each variable in the
data set. These symbols have properties that describe the variable,
such as unit, label, type, etc. plot can make use of this
information when creating plots. Here’s a previous example, where we
do not use variable symbols:
The difference is subtle, but this can save some typing if you are
always adding titles and field types. We don’t use this in the
examples because we want to demonstrate the lowest common denominator,
but in all plots we create professionally we use variable symbols.
Special characters
There are occasions when neither the Parenscript encoder nor Yason
will correctly encode a key or value. In those situations, you’ll
need to use text strings. This can happen when Vega wants an encoding
that includes a character that is a reader macro, #, often used in
color specifications, or in format properties, like this one
(:format ".1~%")
Finally, there may be times when you need to use multiple escape
characters
instead of quoted strings. Occasionally an imported data set will
include parenthesis (). The data-frame reader will enclose these
in multiple escape characters, so for example a variable named body mass (g) will be loaded as |BODY-MASS-(G)|. In these cases you can
either change the name to a valid Common Lisp identifier using
rename-column!, or refer to the variable using the multiple escape
characters.
nil, null, false, true
Strictly speaking, false in JavaScript is the Boolean negative. In
practice, "false", a string, is often accepted. This seems to vary
within Vega-Lite. Some parts accept "false", others do not. The
plot symbol encoder will correctly output false for the symbol
:false, and you should use that anywhere you encounter a Boolean
negative.
true is encoded for the lisp symbol T.
nil and null may be entered directly as they are and will be
correctly transcribed.
Embedded data
By default, plot embeds data within the Vega-Lite JSON spec, then
uses vega-embed to display it
within an HTML page. The alternative is to use data from a
url. Both are
mostly equivalent, however there can be differences in parsing,
especially with dates. When data is embedded, values are parsed by
the JavaScript parse in your browser. When it’s loaded via a url,
it’s run through the Vega-Lite parser. Sometimes Vega-Lite needs a
bit of help by way
of format for
embedded data. For this reason plot always outputs dates & times in
ISO-8601 format, which works everywhere.
Large data sets can be problematic if you have a number of plots open
and limited memory.
Saving plots
You can save plot specifications like any other Common Lisp object,
for example using with-open-file. data-frames also have read/write
functions. This section describes some convenience functions for plot
I/O.
Devices
A ‘device’ is a loose abstraction for the various locations that data
and specifications can be written to. For example in developing this
website, data is written to a directory for static files
/static/data/, and the plot specification to /static/plots/. We
can model this with a plist like so:
and all the bits will be saved to their proper locations. See the
examples at the bottom of the file PLOT:SRC;VEGA;device.lisp for
various ways to use devices and the heuristics for determining
where/when/what to write. These devices have worked in practice in
generating more than 300 plots, but if you encounter a use case that’s
not covered, please open an
issue.
Vega quirks
Vega and Vega-Lite have more than their fair share of quirks and
inconsistencies. For the most part you’ll only notice this in the
‘grammar’ of the graphics specification, however occasionally they may
look like bugs.
When using the bin transformation, Vega-Lite assumes that if you
don’t provide the variable identifier to store the end of the bin, it
will use the name of the start of the bin, suffixed with _end. Many
of the Vega-Lite examples make this assumption. For example, this is
the snippet from a Vega-Lite example:
Noticed the bin is using as: bin_Horsepower and then later, in
the groupBy transformation, referring to bin_Horsepower_end. To
work around this ‘feature’, we need to specify both the start and end
for the bin operation:
This kind of behaviour may occur elsewhere, and it’s not well
documented, so just be careful when you see any kind of beginning or
end encoding in a Vega-Lite example.
Workflow
There are many possible workflows when plotting. This section
describes a few that I’ve found useful when developing plots.
By default, plot will embed data in an HTML file and then call the
systems browser to open it. This is a perfectly fine way to develop plots,
especially if you’re on a machine with a good amount of RAM.
Vega-Desktop
The Vega-Desktop
sadly now unmaintained, still works fine for Vega-Lite up to version
5. With this desktop application, you can drag a plot specification
to the application and ‘watch’ it. Once watched, any changes you make
are instantly updated in the application window. Here’s a
demonstration:
First, set up a ‘device’ to use a directory on the desktop for
plotting:
(defparameter vdsk1 '(:spec-loc #P"~/Desktop/plots/"
:data-loc #P"~/Desktop/plots/data/")
"Put data into a data/ subdirectory")
Now drag the file ~/Desktop/plots/hp-mpg.vl.json to the Vega-Desktop
application:
and click on the ‘watch’ button:
now go back to the buffer with the spec and add a title:
(vega:plot-to-device vdsk1
(vega:defplot hp-mpg
`(:title "Horsepower vs. Miles per Gallon"
:data (:values ,vgcars)
:mark :point
:encoding (:x (:field :horsepower :type "quantitative")
:y (:field :miles-per-gallon :type "quantitative")))))
and reevaluate the form. If you’re in emacs, this is the C-x C-e
command. Observe how the plot is instantly updated:
I tend to use this method when I’m tweaking a plot for final
publication.
Vega edit
You can publish a plot specification to a Github gist and then invoke the Vega editor. This isn’t quite as real-time as Vega Desktop in that changes in the Lisp image aren’t automatically reflected and you’ll have to re-publish. It is a good way to debug plots and download them in various formats, or for sharing.
To use this mechanism, you’ll need to configure two environment variables so the gist wrapper will be able to use your credentials to authenticate to the Github API. Set the following environment variables to hold your github credentials:
GITHUB_USERNAME
GITHUB_OAUTH_TOKEN
Github no longer works with a password, so don’t bother setting that. If you want a custom scheme for authentication, you can create one by following the examples in examples/1.credentials.lisp
Now, you can edit the hp-mpg plot online with:
(vega:edit hp-mpg)
Debugging
There are a couple of commonly encountered scenarios when plots don’t display correctly:
it’s so broken the browser displays nothing
the ... button appears, but the plot is broken
Nothing is displayed
In this case, your best option is to print to a device where you can
examine the output. I use the Vega-Desktop (vgdsk1) so often it’s
part of my Lisp-Stat initialisation, and I also use it for these
cases. Once you’ve got the spec written out as JSON, see if
Vega-Desktop can render it, paying attention to the warnings.
Vega-Desktop also has a debug function:
If Vega-Desktop doesn’t help, open the file in Visual Studio code,
which has a schema validator. Generally these kinds of syntax errors
are easy to spot once they’re pointed out by Visual Studio.
Something is displayed
If you see the three ellipses, then you can open the plot in the
online vega editor. This is very similar to Vega Desktop, but with
one important difference: you can only debug plots with embedded data
sets or remotely available URLs. Because the online editor is a web
application hosted on Github, you can’t access local data sets. This
is one reason I typically use the Vega-Desktop / Visual Studio
combination.
Getting plot information
There are two ways to get information about the plots in your
environment.
show-plots
The show-plots command will display the plots you have defined,
along with a description (if one was provided in the spec). Here are
the plots currently in my environment:
LS-USER> (vega:show-plots)
0: #<PLOT GROUPED-BAR-CHART: Bar chart
NIL>
1: #<PLOT HP-MPG-PLOT: Scatter plot
NIL>
2: #<PLOT HP-MPG: Scatter plot
Horsepower vs miles per gallon for various cars>
Only the last, from the example above, has a description.
describe
You can also use the describe command to view plot information:
LS-USER> (describe hp-mpg)
HP-MPG
Scatter plot of VGCARS
Horsepower vs miles per gallon for various cars
inspect
By typing the plots name in the emacs REPL, a ‘handle’ of sorts is
returned, printed in orange:
Right click on the orange text to get a context menu allowing various
operations on the object, one of which is to ‘inspect’ the object.
Included datasets
The vega package includes all the data sets in the vega data
sets. They
have the same name, in the vega package, e.g. vega:penguins.
5 - System Manuals
Manuals for Lisp-Stat systems
This section describes the core APIs and systems that comprise Lisp-Stat. These APIs include both the high level functionality described elsewhere, as well as lower level APIs that they are built on. This section will be of interest to ‘power users’ and developers who wish to extend Lisp-Stat, or build modules of their own.
5.1 - Array Operations
Manipulating sample data as arrays
Overview
The array-operations system contains a collection of functions and
macros for manipulating Common Lisp arrays and performing numerical
calculations with them.
Array-operations is a ‘generic’ way of operating on array like data
structures. Several aops functions have been implemented for
data-frame. For those that haven’t, you can transform arrays to
data frames using the df:matrix-df function, and a data-frame to an
array using df:as-array. This make it convenient to work with the
data sets using either system.
Quick look
Arrays can be created with numbers from a statistical distribution:
(defparameter A #2A((1 2)
(3 4)))
(defparameter B #2A((2 3)
(4 5)))
;; split along any dimension
(split A 1) ; => #(#(1 2) #(3 4))
;; stack along any dimension
(stack 1 A B) ; => #2A((1 2 2 3)
; (3 4 4 5))
;; element-wise function map
(each #'+ #(0 1 2) #(2 3 5)) ; => #(2 4 7)
;; element-wise expressions
(vectorize (A B) (* A (sqrt B))) ; => #2A((1.4142135 3.4641016)
; (6.0 8.944272))
;; index operations e.g. matrix-matrix multiply:
(each-index (i j)
(sum-index k
(* (aref A i k) (aref B k j)))) ; => #2A((10 13)
; (22 29))
Array shorthand
The library defines the following short function names that are synonyms
for Common Lisp operations:
array-operations
Common Lisp
size
array-total-size
rank
array-rank
dim
array-dimension
dims
array-dimensions
nrow
number of rows in matrix
ncol
number of columns in matrix
The array-operations package has the nickname aops, so you can use,
for example, (aops:size my-array) without use‘ing the package.
Displaced arrays
According to the Common Lisp specification, a displaced array is:
An array which has no storage of its own, but which
is instead indirected to the storage of another array, called its
target, at a specified offset, in such a way that any attempt to
access the displaced array implicitly references the target array.
Displaced arrays are one of the niftiest features of Common Lisp. When
an array is displaced to another array, it shares structure with (part
of) that array. The two arrays do not need to have the same dimensions,
in fact, the dimensions do not be related at all as long as the
displaced array fits inside the original one. The row-major index of the
former in the latter is called the offset of the displacement.
displace
Displaced arrays are usually constructed using make-array, but this
library also provides displace for that purpose:
Functions in the library accept the following in place of dimensions:
a list of dimensions (as for make-array),
a positive integer, which is used as a single-element list,
another array, the dimensions of which are used.
The last one allows you to specify dimensions with other arrays. For
example, to reshape an array a1 to look like a2, you can use
(aops:reshape a1 a2)
instead of the longer form
(aops:reshape a1 (aops:dims a2))
Creation & transformation
Use the functions in this section to create commonly used arrays
types. When the resulting element type cannot be inferred from an
existing array or vector, you can pass the element type as an optional
argument. The default is elements of type T.
Element traversal order of these functions is unspecified. The
reason for this is that the library may use parallel code in the
future, so it is unsafe to rely on a particular element traversal
order.
The following functions all make a new array, taking the dimensions as
input. There are also versions ending in ! which do not make a
new array, but take an array as first argument, which is modified and
returned.
Function
Description
zeros
Filled with zeros
ones
Filled with ones
rand
Filled with uniformly distributed random numbers between 0 and 1
randn
Normally distributed with mean 0 and standard deviation 1
linspace
Evenly spaced numbers in given range
For example:
(aops:zeros 3)
; => #(0 0 0)
(aops:zeros 3 'double-float)
; => #(0.0d0 0.0d0 0.0d0)
(aops:rand '(2 2))
; => #2A((0.6686077 0.59425664)
; (0.7987722 0.6930506))
(aops:rand '(2 2) 'single-float)
; => #2A((0.39332366 0.5557821)
; (0.48831415 0.10924244))
(let ((a (make-array '(2 2) :element-type 'double-float)))
;; Modify array A, filling with random numbers
;; element type is taken from existing array
(aops:rand! a))
; => #2A((0.6324615478515625d0 0.4636608362197876d0)
; (0.4145939350128174d0 0.5124958753585815d0))
permute can permute subscripts (you can also invert, complement, and
complete permutations, look at the docstring and the unit tests).
Transposing is a special case of permute:
vectorize is a macro which performs elementwise operations
(defparameter a #(1 2 3 4))
(aops:vectorize (a) (* 2 a)) ; => #(2 4 6 8)
(defparameter b #(2 3 4 5))
(aops:vectorize (a b) (* a (sin b)))
; => #(0.9092974 0.28224 -2.2704074 -3.8356972)
There is also a version vectorize* which takes a type argument for the
resulting array, and a version vectorize! which sets elements in a
given array.
margin
The semantics of margin are more difficult to explain, so perhaps an
example will be more useful. Suppose that you want to calculate column
sums in a matrix. You could permute (transpose) the matrix, split
its sub-arrays at rank one (so you get a vector for each row), and apply
the function that calculates the sum. margin automates that for you:
But the function is more general than this: the arguments inner and
outer allow arbitrary permutations before splitting.
recycle
Finally, recycle allows you to reuse the elements of the first argument, object, to create new arrays by extending the dimensions. The :outer keyword repeats the original object and :inner keyword argument repeats the elements of object. When both :inner and :outer are nil, object is returned as is. Non-array objects are intepreted as rank 0 arrays, following the usual semantics.
Three dimensional arrays can be tough to get your head around. In the example above, :outer asks for 4 2-element vectors, composed of repeating the elements of object twice, i.e. repeat ‘2’ twice and repeat ‘3’ twice. Compare this with :inner as 3:
The most common use case for recycle is to ‘stretch’ a vector so that it can be an operand for an array of compatible dimensions. In Python, this would be known as ‘broadcasting’. See the Numpy broadcasting basics for other use cases.
For example, suppose we wish to multiply array a, a size 4x3 with vector b of size 3, as in the figure below:
In a similar manner, the figure below (also from the Numpy page) shows how we might stretch a vector horizontally to create an array compatible with the one created above.
To create that array from a vector, use the :inner keyword:
turn rotates an array by a specified number of clockwise 90° rotations. The axis of rotation is specified by RANK-1 (defaulting to 0) and RANK-2 (defaulting to 1). In the first example, we’ll rotate by 90°:
outer is generalized outer product of arrays using a provided function.
Lambda list: (function &rest arrays)
The resulting array has the concatenated dimensions of arrays
The examples below return the outer
product of vectors or arrays. This is the outer product you get in most linear algebra packages.
(defparameter a #(2 3 5))
(defparameter b #(7 11))
(defparameter c #2A((7 11)
(13 17)))
(outer #'* a b)
;#2A((14 22)
; (21 33)
; (35 55))
(outer #'* c a)
;#3A(((14 21 35) (22 33 55))
; ((26 39 65) (34 51 85)))
Indexing operations
nested-loop
nested-loop is a simple macro which iterates over a set of indices
with a given range
(defparameter A #2A((1 2) (3 4)))
(aops:nested-loop (i j) (array-dimensions A)
(setf (aref A i j) (* 2 (aref A i j))))
A ; => #2A((2 4) (6 8))
(aops:nested-loop (i j) '(2 3)
(format t "(~a ~a) " i j)) ; => (0 0) (0 1) (0 2) (1 0) (1 1) (1 2)
sum-index
sum-index is a macro which uses a code walker to determine the
dimension sizes, summing over the given index or indices
(defparameter A #2A((1 2) (3 4)))
;; Trace
(aops:sum-index i (aref A i i)) ; => 5
;; Sum array
(aops:sum-index (i j) (aref A i j)) ; => 10
;; Sum array
(aops:sum-index i (row-major-aref A i)) ; => 10
The main use for sum-index is in combination with each-index.
each-index
each-index is a macro which creates an array and iterates over the
elements. Like sum-index it is given one or more index symbols, and
uses a code walker to find array dimensions.
(defparameter A #2A((1 2)
(3 4)))
(defparameter B #2A((5 6)
(7 8)))
;; Transpose
(aops:each-index (i j) (aref A j i)) ; => #2A((1 3)
; (2 4))
;; Sum columns
(aops:each-index i
(aops:sum-index j
(aref A j i))) ; => #(4 6)
;; Matrix-matrix multiply
(aops:each-index (i j)
(aops:sum-index k
(* (aref A i k) (aref B k j)))) ; => #2A((19 22)
; (43 50))
reduce-index
reduce-index is a more general version of sum-index; it
applies a reduction operation over one or more indices.
(defparameter A #2A((1 2)
(3 4)))
;; Sum all values in an array
(aops:reduce-index #'+ i (row-major-aref A i)) ; => 10
;; Maximum value in each row
(aops:each-index i
(aops:reduce-index #'max j
(aref A i j))) ; => #(2 4)
Reducing
Some reductions over array elements can be done using the Common Lisp
reduce function, together with aops:flatten, which returns a
displaced vector:
argmax and argmin find the row-major-aref index where an
array value is maximum or minimum. They both return two values: the
first value is the index; the second is the array value at that index.
(defparameter a #(1 2 5 4 2))
(aops:argmax a) ; => 2 5
(aops:argmin a) ; => 0 1
vectorize-reduce
More complicated reductions can be done with vectorize-reduce,
for example the maximum absolute difference between arrays:
(defparameter a #2A((1 2)
(3 4)))
(defparameter b #2A((2 2)
(1 3)))
(aops:vectorize-reduce #'max (a b) (abs (- a b))) ; => 2
best
best compares two arrays according to a function and returns the ‘best’ value found. The function, FN must accept two inputs and return true/false. This function is applied to elements of ARRAY. The row-major-aref index is returned.
Example: The index of the maximum is
* (best #'> #(1 2 3 4))
3 ; row-major index
4 ; value
most
most finds the element of ARRAY that returns the value closest to positive infinity when FN is applied to the array value. Returns the row-major-aref index, and the winning value.
Library functions treat non-array objects as if they were equivalent to
0-dimensional arrays: for example, (aops:split array (rank array))
returns an array that effectively equivalent (eq) to array. Another
example is recycle:
You can stack compatible arrays by column or row. Metaphorically you
can think of these operations as stacking blocks. For example stacking
two row vectors yields a 2x2 array:
(stack-rows #(1 2) #(3 4))
;; #2A((1 2)
;; (3 4))
Like other functions, there are two versions: generalised stacking,
with rows and columns of type T and specialised versions where the
element-type is specified. The versions allowing you to specialise
the element type end in *.
The stack functions use object dimensions (as returned by dims to
determine how to use the object.
when the object has 0 dimensions, fill a column with the element
when the object has 1 dimension, use it as a column
when the object has 2 dimensions, use it as a matrix
copy-row-major-block is a utility function in the stacking package
that does what it suggests; it copies elements from one array to
another. This function should be used to implement copying of
contiguous row-major blocks of elements.
rows
stack-rows-copy is the method used to implement the copying of objects in stack-row*, by copying the elements of source to destination, starting with the row index start-row in the latter. Elements are coerced to element-type.
stack-rows and stack-rows* stack objects row-wise into an array of the given element-type, coercing if necessary. Always return a simple array of rank 2. stack-rows always returns an array with elements of type T, stack-rows* coerces elements to the specified type.
columns
stack-cols-copy is a method used to implement the copying of objects in stack-col*, by copying the elements of source to destination, starting with the column index start-col in the latter. Elements are coerced to element-type.
stack-cols and stack-cols* stack objects column-wise into an array of the given element-type, coercing if necessary. Always return a simple array of rank 2. stack-cols always returns an array with elements of type T, stack-cols* coerces elements to the specified type.
arbitrary
stack and stack* stack array arguments along axis. element-type determines the element-type
of the result.
A common lisp data frame is a collection of observations of sample
variables that shares many of the properties of arrays and lists. By
design it can be manipulated using the same mechanisms used to
manipulate lisp arrays. This allow you to, for example, transform a
data frame into an array and use
array-operations to manipulate it, and
then turn it into a data frame again to use in modeling or plotting.
Data frame is implemented as a two-dimensional common lisp data
structure: a vector of vectors for data, and a hash table mapping
variable names to column vectors. All columns are of equal length.
This structure provides the flexibility required for column oriented
manipulation, as well as speed for large data sets.
Note
In this document we refer to column and
variable interchangeably. Likewise factor and category refer to a
variable type. Where necessary we distinguish the terminology.
Load/install
Data-frame is part of the Lisp-Stat package. It can be used
independently if desired. Since the examples in this manual use
Lisp-Stat functionality, we’ll use it from there rather than load
independently.
(ql:quickload :lisp-stat)
Within the Lisp-Stat system, the LS-USER package is the package for
you to do statistics work. Type the following to change to that
package:
(in-package :ls-user)
Note
The examples assume that you are in package
LS-USER. You should make a habit of always working from the LS-USER
package. All the samples may be copied to the clipboard using the
copy button in the upper-right corner of the sample code
box.
Naming conventions
Lisp-Stat has a few naming conventions you should be aware of. If you
see a punctuation mark or the letter ‘p’ as the last letter of a
function name, it indicates something about the function:
‘!’ indicates that the function is destructive. It will modify the data that you pass to it. Otherwise, it will return a copy that you will need to save in a variable.
‘p’, ‘-p’ or ‘?’ means the function is a predicate, that is returns a Boolean truth value.
Data frame environment
Although you can work with data frames bound to symbols (as would
happen if you used (defparameter ...), it is more convenient to
define them as part of an environment. When you do this, the system
defines a package of the same name as the data frame, and provides a
symbol for each variable. Let’s see how things work without an
environment:
First, we define a data frame as a parameter:
(defparameter mtcars (read-csv rdata:mtcars)
"Motor Trend Car Road Tests")
;; WARNING: Missing column name was filled in
;; MTCARS2
Now if we want a column, we can say:
(column mtcars 'mpg)
Now let’s define an environment using defdf:
(defdf mtcars (read-csv rdata:mtcars)
"Motor Trend Car Road Tests")
;; WARNING: Missing column name was filled in
;; #<DATA-FRAME (32 observations of 12 variables)
;; Motor Trend Car Road Tests>
Now we can access the same variable with:
mtcars:mpg
defdf does a lot more than this, and you should probably use defdf to set up an environment instead of defparameter. We mention it here because there’s an important bit about maintaining the environment to be aware of:
Note
Destructive functions (those ending in ‘!’), will automatically update the environment for you. Functions that return a copy of the data will not.
defdf
The defdf macro is conceptually equivalent to the Common
Lisp defparameter, but with some additional functionality that makes
working with data frames easier. You use it the same way you’d use
defparameter, for example:
(defdf foo <any-function returning a data frame> )
We’ll use both ways of defining data frames in this manual. The access
methods that are defined by defdf are described in the
access data section.
Data types
It is important to note that there are two ’types’ in Lisp-Stat: the
implementation type and the ‘statistical’ type. Sometimes these are
the same, such as in the case of reals; in other situations they are
not. A good example of this can be seen in the mtcars data set. The
hp (horsepower), gear and carb are all of type integer from an
implementation perspective. However only horsepower is a continuous
variable. You can have an additional 0.5 horsepower, but you cannot
add an additional 0.5 gears or carburetors.
Data types are one kind of property that can be set on a variable.
As part of the recoding and data cleansing process, you will want to add
properties to your variables. In Common Lisp, these are plists that
reside on the variable symbols, e.g. mtcars:mpg. In R they are
known as attributes. By default, there are three properties for
each variable: type, unit and label (documentation). When you load
from external formats, like CSV, these properties are all nil; when
you load from a lisp file, they will have been saved along with the
data (if you set them).
There are seven data types in Lisp-Stat:
string
integer
double-float
single-float
categorical (factor in R)
temporal
bit (Boolean)
Numeric
Numeric types, double-float, single-float and integer are all
essentially similar. The vector versions have type definitions (from
the numeric-utilities package) of:
simple-double-float-vector
simple-single-float-vector
simple-fixnum-vector
As an example, let’s look at mtcars:mpg, where we have a variable of
type float, but a few integer values mixed in.
The values may be equivalent, but the types are not. The CSV
loader has no way of knowing, so loads the column as a mixture of
integers and floats. Let’s start by reloading mtcars from the CSV
file:
Notice that the first two entries in the vector are integers, and the
remainder floats. To fix this manually, you will need to coerce each
element of the column to type double-float (you could use
single-float in this case; as a matter of habit we usually use
double-float) and then change the type of the vector to a
specialised float vector.
You can use the heuristicate-types function to guess the statistical
types for you. For reals and strings, heuristicate-types works
fine, however because integers and bits can be used to encode
categorical or numeric values, you will have to indicate the type
using set-properties. We see this below with gear and carb,
although implemented as integer, they are actually type
categorical. The next sections describes how to set them.
Using describe, we can view the
types of all the variables that heuristicate-types set:
Notice the system correctly typed vs and am as Boolean (bit)
(correct in a mathematical sense)
Strings
Unlike in R, strings are not considered categorical variables by
default. Ordering of strings varies according to locale, so it’s not a
good idea to rely on the strings. Nevertheless, they do work well if
you are working in a single locale.
Categorical
Categorical variables have a fixed and known set of possible values.
In mtcars, gear, carbvs and am are categorical variables,
but heuristicate-types can’t distinguish categorical types, so
we’ll set them:
Dates and times can be surprisingly complicated. To make working with
them simpler, Lisp-Stat uses vectors of
localtime objects to
represent dates & times. You can set a temporal type with
set-properties as well using the keyword :temporal.
Units & labels
To add units or labels to the data frame, use the set-properties
function. This function takes a plist of variable/value pairs, so to
set the units and labels:
LS-USER> (describe mtcars)
MTCARS
A data-frame with 32 observations of 12 variables
Variable | Type | Unit | Label
-------- | ---- | ---- | -----------
X8 | STRING | NIL | NIL
MPG | DOUBLE-FLOAT | M/G | Miles/(US) gallon
CYL | INTEGER | NA | Number of cylinders
DISP | DOUBLE-FLOAT | IN3 | Displacement (cu.in.)
HP | INTEGER | HP | Gross horsepower
DRAT | DOUBLE-FLOAT | NA | Rear axle ratio
WT | DOUBLE-FLOAT | LB | Weight (1000 lbs)
QSEC | DOUBLE-FLOAT | S | 1/4 mile time
VS | BIT | NA | Engine (0=v-shaped, 1=straight)
AM | BIT | NA | Transmission (0=automatic, 1=manual)
GEAR | INTEGER | NA | Number of forward gears
CARB | INTEGER | NA | Number of carburetors
You can set your own properties with this command too. To make your
custom properties appear in the describe command and be saved
automatically, override the describe and write-df methods, or use
:after methods.
Create data-frames
A data frame can be created from a Common Lisp array, alist,
plist, individual data vectors, another data frame or a vector-of
vectors. In this section we’ll describe creating a data frame from each of these.
Data frame columns represent sample set variables, and its rows
are observations (or cases).
Note
For these examples we are going to install a modified version of the
Lisp-Stat data-frame print-object function. This will cause the REPL
to display the data-frame at creation, and save us from having to type
(print-data data-frame) in each example. If you’d like to install it as we
have, execute the code below at the REPL.
(defmethod print-object ((df data-frame) stream)
"Print the first six rows of DATA-FRAME"
(let ((*print-lines* 6))
(df:print-data df stream nil)))
(set-pprint-dispatch 'df:data-frame
#'(lambda (s df) (df:print-data df s nil)))
You can ignore the warning that you’ll receive after executing the
code above.
Let’s create a simple data frame. First we’ll setup some
variables (columns) to represent our sample domain:
(defparameter v #(1 2 3 4)) ; vector
(defparameter b #*0110) ; bits
(defparameter s #(a b c d)) ; symbols
(defparameter plist `(:vector ,v :symbols ,s)) ;only v & s
Let’s print plist. Just type the name in at the REPL prompt.
plist
(:VECTOR #(1 2 3 4) :SYMBOLS #(A B C D))
From p/a-lists
Now suppose we want to create a data frame from a plist
(apply #'df plist)
;; VECTOR SYMBOLS
;; 1 A
;; 2 B
;; 3 C
;; 4 D
We could also have used the plist-df function:
(plist-df plist)
;; VECTOR SYMBOLS
;; 1 A
;; 2 B
;; 3 C
;; 4 D
and to demonstrate the same thing using an alist, we’ll use the
alexandria:plist-alist function to convert the plist into an
alist:
(alist-df (plist-alist plist))
;; VECTOR SYMBOLS
;; 1 A
;; 2 B
;; 3 C
;; 4 D
From vectors
You can use make-df to create a data frame from keys and a list of
vectors. Each vector becomes a column in the data-frame.
(make-df '(:a :b) ; the keys
'(#(1 2 3) #(10 20 30))) ; the columns
;; A B
;; 1 10
;; 2 20
;; 3 30
This is useful if you’ve started working with variables defined with
defparameter or defvar and want to combine them into a data frame.
From arrays
matrix-df converts a matrix (array) to a data-frame with the given
keys.
This is useful if you need to do a lot of numeric number-crunching on
a data set as an array, perhaps with BLAS or array-operations then
want to add categorical variables and continue processing as a
data-frame.
Example datasets
Vincent Arel-Bundock maintains a library of over 1700 R
datasets that is a
consolidation of example data from various R packages. You can load
one of these by specifying the url to the raw data to the read-csv
function. For example to load the
iris
data set, use:
To make the examples and tutorials easier, Lisp-Stat includes the URLs
for the R built in data sets. You can see these by viewing the
rdata:*r-default-datasets* variable:
To load one of these, you can use the name of the data set. For example to load mtcars:
(defdf mtcars
(read-csv rdata:mtcars))
If you want to load all of the default R data sets, use the
rdata:load-r-default-datasets command. All the data sets included in
base R will now be loaded into your environment. This is useful if you
are following a R tutorial, but using Lisp-Stat for the analysis
software.
You may also want to save the default R data sets in order to augment
the data with labels, units, types, etc. To save all of the default R
data sets to the LS:DATA;R directory, use the
(rdata:save-r-default-datasets) command if the default data sets
have already been loaded, or save-r-data if they have not. This
saves the data in lisp format.
Install R datasets
To work with all of the R data sets, we recommend you use git to
download the repository to your hard drive. For example I downloaded the
example data to the s: drive like this:
cd s:
git clone https://github.com/vincentarelbundock/Rdatasets.git
and setup a logical host in my ls-init.lisp file like so:
;;; Define logical hosts for external data sets
(setf (logical-pathname-translations "RDATA")
`(("**;*.*.*" ,(merge-pathnames "csv/**/*.*" "s:/Rdatasets/"))))
Now you can access any of the datasets using the logical
pathname. Here’s an example of creating a data frame using the
ggplotmpg data set:
(defdf mpg (read-csv #P"RDATA:ggplot2;mpg.csv"))
Searching the examples
With so many data sets, it’s helpful to load the index into a data
frame so you can search for specific examples. You can do this by
loading the rdata:index into a data frame:
(defdf rindex (read-csv rdata:index))
I find it easiest to use the SQL-DF system
to query this data. For example if you wanted to find the data sets
with the largest number of observations:
(ql:quickload :sqldf)
(print-data
(sqldf:sqldf "select item, title, rows, cols from rindex order by rows desc limit 10"))
;; ITEM TITLE ROWS COLS
;; 0 military US Military Demographics 1414593 6
;; 1 Birthdays US Births in 1969 - 1988 372864 7
;; 2 wvs_justifbribe Attitudes about the Justifiability of Bribe-Taking in the ... 348532 6
;; 3 flights Flights data 336776 19
;; 4 wvs_immig Attitudes about Immigration in the World Values Survey 310388 6
;; 5 Fertility Fertility and Women's Labor Supply 254654 8
;; 6 avandia Cardiovascular problems for two types of Diabetes medicines 227571 2
;; 7 AthleteGrad Athletic Participation, Race, and Graduation 214555 3
;; 8 mortgages Data from "How do Mortgage Subsidies Affect Home Ownership? ..." 214144 6
;; 9 mammogram Experiment with Mammogram Randomized
Export data frames
These next few functions are the reverse of the ones above used to
create them. These are useful when you want to use foreign libraries
or common lisp functions to process the data.
For this section of the manual, we are going to work with a subset of
the mtcars data set from above. We’ll use the
select package to take the first 5 rows so that
the data transformations are easier to see.
The next three functions convert a data-frame to and from standard
common lisp data structures. This is useful if you’ve got data in
Common Lisp format and want to work with it in a data frame, or if
you’ve got a data frame and want to apply Common Lisp operators on it
that don’t exist in df.
as-alist
Just like it says on the tin, as-alist takes a data frame and
returns an alist version of it (formatted here for clearer output –
a pretty printer that outputs an alist in this format would be a
welcome addition to Lisp-Stat)
as-array returns the data frame as a row-major two dimensional lisp
array. You’ll want to save the variable names using the
keys function to make it easy to
convert back (see matrix-df). One of the reasons you
might want to use this function is to manipulate the data-frame using
array-operations. This is
particularly useful when you have data frames of all numeric values.
Our abbreviated mtcars data frame is now a two dimensional Common
Lisp array. It may not look like one because Lisp-Stat will ‘print
pretty’ arrays. You can inspect it with the describe command to make
sure:
LS-USER> (describe mtcars-small-array)
...
Type: (SIMPLE-ARRAY T (5 12))
Class: #<BUILT-IN-CLASS SIMPLE-ARRAY>
Element type: T
Rank: 2
Physical size: 60
vectors
The columns function returns the variables of the data frame as a vector of
vectors:
The functions in array-operations are
helpful in further dealing with data frames as vectors and arrays. For
example you could convert a data frame to a transposed array by using
aops:combine with the
columns function:
There are two functions for loading data. The first data makes
loading from logical pathnames convenient. The other, read-csv
works with the file system or URLs. Although the name read-csv
implies only CSV (comma separated values), it can actually read with
other delimiters, such as the tab character. See the DFIO API
reference for more information.
The data command
For built in Lisp-Stat data sets, you can load with just the data set
name. For example to load mtcars:
(data :mtcars)
If you’ve installed the R data
sets, and want to load
the antigua data set from the daag package, you could do it like
this:
dfio tries to hard to decipher the various number formats sometimes
encountered in CSV files:
(select (dfio:read-csv
(format nil "\"All kinds of wacky number formats\"~%.7~%19.~%.7f2"))
t 'all-kinds-of-wacky-number-formats)
; => #(0.7d0 19.0d0 70.0)
From delimited files
We saw above that dfio can read from strings, so one easy way to
read from a file is to use the uiop system function
read-file-string. We can read one of the example data files
included with Lisp-Stat like this:
That example just illustrates reading from a file to a string. In
practice you’re better off just reading the file in directly and avoid
reading into a string first:
dfio can also read from Common Lisp
streams.
Stream operations can be network or file based. Here is an example
of how to read the classic Iris data set over the network:
Note that sqlite:connect does not take a logical pathname; use a
system path appropriate for your computer. One reason you might want
to do this is for speed in loading CSV. The CSV loader for SQLite is
10-15 times faster than the fastest Common Lisp CSV parser, and it is
often quicker to load to SQLite first, then load into Lisp.
Save data
Data frames can be saved into any delimited text format supported by
fare-csv, or several
flavors of JSON, such as Vega-Lite.
As CSV
To save the mtcars data frame to disk, you could use:
For the most part, you will want to save your data frames as
lisp. Doing so is both faster in loading, but more importantly it
preserves any variable attributes that may have been given.
To save a data frame, use the save command:
(save 'mtcars #P"LS:DATA;mtcars-example")
Note that in this case you are passing the symbol to the function,
not the value (thus the quote (’) before the name of the data frame).
Also note that the system will add the ’lisp’ suffix for you.
To a database
The write-table function
can be used to save a data frame to a SQLite database. Each take a
connection to a database, which may be file or memory based, a table
name and a data frame. Multiple data frames, with different table
names, may be written to a single SQLite file this way.
Access data
This section describes various way to access data variables.
Define a data-frame
Let’s use defdf to define the iris data
frame. We’ll use both of these data frames in the examples below.
(defdf iris
(read-csv rdata:iris))
;WARNING: Missing column name was filled in
We now have a global
variable
named iris that represents the data frame. Let’s look at the first
part of this data:
Notice a couple of things. First, there is a column X29. In fact if
you look back at previous data frame output in this tutorial you will
notice various columns named X followed by some number. This is
because the column was not given a name in the data set, so a name was
generated for it. X starts at 1 and increased by 1 each time an
unnamed variable is encountered during your Lisp-Stat session. The
next time you start Lisp-Stat, numbering will begin from 1 again.
We will see how to clean this up this data frame in the next sections.
The second thing to note is the row numbers on the far left side.
When Lisp-Stat prints a data frame it automatically adds row
numbers. Row and column numbering in Lisp-Stat start at 0. In R they
start with 1. Row numbers make it convenient to select data sections
from a data frame, but they are not part of the data and cannot be
selected or manipulated themselves. They only appear when a data
frame is printed.
Access a variable
The defdf macro also defines symbol macros that allow you to refer
to a variable by name, for example to refer to the mpg column of
mtcars, you can refer to it by the the name data-frame:variable
convention.
There is a point of distinction to be made here: the values of mpg
and the columnmpg. For example to obtain the same vector using
the selection/sub-setting package select we must refer to the
column:
Note that with select we passed the symbol'mpg (you can
tell it’s a symbol because of the quote in front of it).
So, the rule here is: if you want the value refer to it directly,
e.g. mtcars:mpg. If you are referring to the column, use the
symbol. Data frame operations sometimes require the symbol, where as
Common Lisp and other packages that take vectors use the direct access
form.
Data-frame operations
These functions operate on data-frames as a whole.
copy
copy returns a newly allocated data-frame with the same values as
the original:
By default only the keys are copied and the original data remains the
same, i.e. a shallow copy. For a deep copy, use the copy-array
function as the key:
Useful when applying destructive operations to the data-frame.
keys
Returns a vector of the variables in the data frame. The keys are
symbols. Symbol properties describe the variable, for example units.
(keys mtcars)
; #(X45 MPG CYL DISP HP DRAT WT QSEC VS AM GEAR CARB)
Recall the earlier discussion of X1 for the column name.
map-df
map-df transforms one data-frame into another, row-by-row. Its
function signature is:
(map-df data-frame keys function result-keys) ...
It applies function to each row, and returns a data frame with the
result-keys as the column (variable) names. keys is a list.
You can also specify the type of the new variables in the
result-keys list.
into a data-frame that consists of the product of :a and :b, and a
bit mask of the columns that indicate where the value is <= 30. First
we’ll need a helper for the bit mask:
(defun predicate-bit (a b)
"Return 1 if a*b <= 30, 0 otherwise"
(if (<= 30 (* a b))
1
0))
Now we can transform df1 into our new data-frame, df2, with:
(defparameter df2 (map-df df1
'(:a :b)
(lambda (a b)
(vector (* a b) (predicate-bit a b)))
'((:p fixnum) (:m bit))))
Since it was a parameter assignment, we have to view it manually:
(print-df df2)
;; P M
;; 0 14 0
;; 1 33 1
;; 2 65 1
Note how we specified both the new key names and their type. Here’s
an example that transforms the units of mtcars from imperial to metric:
Note that you may have to adjust the X column name to suit your
current environment.
You might be wondering how we were able to refer to the columns
without the ’ (quote); in fact we did, at the beginning of the
list. The lisp reader then reads the contents of the list as symbols.
print
The print-data command will print a data frame in a nicely formatted
way, respecting the pretty printing row/column length variables:
The df-remove-duplicates function will remove duplicate rows. Let’s
create a data-frame with duplicates:
(defparameter dup (make-df '(a b c) '(#(a1 a1 a3)
#(a1 a1 b3)
#(a1 a1 c3))))
;DUP
;; A B C
;; 0 A1 A1 A1
;; 1 A1 A1 A1
;; 2 A3 B3 C3
Now remove duplicate rows 0 and 1:
(df-remove-duplicates dup)
;; A B C
;; A1 A1 A1
;; A3 B3 C3
remove data-frame
If you are working with large data sets, you may wish to remove a data
frame from your environment to save memory. The undef command does
this:
LS-USER> (undef 'tooth-growth)
(TOOTH-GROWTH)
You can check that it was removed with the show-data-frames
function, or by viewing the list df::*data-frames*.
list data-frames
To list the data frames in your environment, use the
show-data-frames function. Here is an example of what is currently
loaded into the authors environment. The data frames listed may be
different for you, depending on what you have loaded.
To see this output, you’ll have to change to the standard
print-object method, using this code:
(defmethod print-object ((df data-frame) stream)
"Print DATA-FRAME dimensions and type
After defining this method it is permanently associated with data-frame objects"
(print-unreadable-object (df stream :type t)
(let ((description (and (slot-boundp df 'name)
(documentation (find-symbol (name df)) 'variable))))
(format stream
"(~d observations of ~d variables)"
(aops:nrow df)
(aops:ncol df))
(when description
(format stream "~&~A" (short-string description))))))
Now, to see all the data frames in your environment:
LS-USER> (show-data-frames)
#<DATA-FRAME AQ (153 observations of 7 variables)>
#<DATA-FRAME MTCARS (32 observations of 12 variables)
Motor Trend Car Road Tests>
#<DATA-FRAME USARRESTS (50 observations of 5 variables)
Violent Crime Rates by US State>
#<DATA-FRAME PLANTGROWTH (30 observations of 3 variables)
Results from an Experiment on Plant Growth>
#<DATA-FRAME TOOTHGROWTH (60 observations of 4 variables)
The Effect of Vitamin C on Tooth Growth in Guinea Pigs>
with the :head t option, show-data-frames will print the first
five rows of the data frame, similar to the head command:
There are two ‘flavors’ of add functions, destructive and
non-destructive. The latter return a new data frame as the
result, and the destructive versions modify the data frame passed as a
parameter. The destructive versions are denoted with a ‘!’ at the end
of the function name.
The columns to be added can be in several formats:
plist
alist
(plist)
(alist)
(data-frame)
To add a single column to a data frame, use the add-column!
function. We’ll use a data frame similar to the one used in our
reading data-frames from a string example to illustrate column
operations.
now that we have weight, let’s add a BMI column to it to demonstrate
using a function to compute the new column values:
(add-column! *d* 'bmi
(map-rows *d* '(height weight)
#'(lambda (h w) (/ w (square (/ h 100))))))
;; SEX AGE HEIGHT WEIGHT BMI
;; 0 Female 10 180 75.2 23.209875
;; 1 Female 15 182 88.5 26.717787
;; 2 Male 20 165 49.4 18.145086
;; 3 Female 25 167 78.1 28.003874
;; 4 Male 30 170 79.4 27.474049
Now let’s add multiple columns destructively using add-columns!
(add-columns! *d* 'a #(1 2 3 4 5) 'b #(foo bar baz qux quux))
;; GENDER AGE HEIGHT WEIGHT BMI A B
;; Male 30 180 75.2 23.2099 1 FOO
;; Male 31 182 88.5 26.7178 2 BAR
;; Female 32 165 49.4 18.1451 3 BAZ
;; Male 22 167 78.1 28.0039 4 QUX
;; Female 45 170 79.4 27.4740 5 QUUX
remove columns
Let’s remove the columns a and b that we just added above with
the remove-columns function. Since it returns a new data frame,
we’ll need to assign the return value to *d*:
(setf *d* (remove-columns *d* '(a b bmi)))
;; GENDER AGE HEIGHT WEIGHT BMI
;; Male 30 180 75.2 23.2099
;; Male 31 182 88.5 26.7178
;; Female 32 165 49.4 18.1451
;; Male 22 167 78.1 28.0039
;; Female 45 170 79.4 27.4740
To remove columns destructively, meaning modifying the original data,
use the remove-column! or remove-columns! functions.
rename columns
Sometimes data sources can have variable names that we want to change.
To do this, use the rename-column! function. This example will
rename the ‘gender’ variable to ‘sex’:
(rename-column! *d* 'sex 'gender)
;; SEX AGE HEIGHT WEIGHT
;; 0 Male 30 180 75.2
;; 1 Male 31 182 88.5
;; 2 Female 32 165 49.4
;; 3 Male 22 167 78.1
;; 4 Female 45 170 79.4
If you used defdf to create your data frame, and this is the
recommended way to define data frames, the variable references within
the data package will have been updated. This is true for all
destructive data frame operations. Let’s use this now to rename the
mtcarsX1 variable to model. First a quick look at the first 2
rows as they are now:
replace-column! can also apply functions to a column, destructively
modifying the column.
map-columns
The map-columns functions can be thought of as applying a function
on all the values of each variable/column as a vector, rather than the
individual rows as replace-column does. To see this, we’ll use
functions that operate on vectors, in this case nu:e+, which is the
vector addition function for Lisp-Stat. Let’s see this working first:
(nu:e+ #(1 1 1) #(2 3 4))
; => #(3 4 5)
observe how the vectors were added element-wise. We’ll demonstrate
map-columns by adding one to each of the numeric columns in the
example data frame:
recall that we used the non-destructive version of replace-column
above, so *d* has the original values. Also note the use of select
to get the numeric variables from the data frame; e+ can’t add
categorical values like gender/sex.
Row operations
As the name suggests, row operations operate on each row, or
observation, of a data set.
add rows
Adding rows is done with the array-operations stacking functions. Since these functions operate on both arrays and data frames, we can use them to stack data frames, arrays, or a mixture of both, providing they have a rank of 2. Here’s an example of adding a row to the mtcars data frame:
This is the functional equivalent of R’s rbind function. You can also add columns with the stack-cols function.
An often asked question is: why don’t you have a dedicated stack-rows function? Well, if you want one it might look like this:
(defun stack-rows (df &rest objects)
"Stack rows that works on matrices and/or data frames."
(matrix-df
(keys df)
(apply #'aops:stack-rows (cons df objects))))
But now the data frame must be the first parameter passed to the function. Or perhaps you want to rename the columns? Or you have matrices as your starting point? For all those reasons, it makes more sense to pass in the column keys than a data frame:
(defun stack-rows (col-names &rest objects)
"Stack rows that works on matrices and/or data frames."
(matrix-df
(keys col-names)
(stack-rows objects)))
However this means we have two stack-rows functions, and you don’t really gain anything except an extra function call. So use the above definition if you like; we use the first example and call matrix-df and stack-rows to stack data frames.
count-rows
This function is used to determine how many rows meet a certain
condition. For example if you want to know how many cars have a MPG
(miles-per-galleon) rating greater than 20, you could use:
do-rows applies a function on selected variables. The function must
take the same number of arguments as variables supplied. It is
analogous to dotimes, but
iterating over data frame rows. No values are returned; it is purely
for side-effects. Let’s create a new data data-frame to
illustrate row operations:
LS-USER> (defparameter *d2*
(make-df '(a b) '(#(1 2 3) #(10 20 30))))
*D2*
LS-USER> *d2*
;; A B
;; 0 1 10
;; 1 2 20
;; 2 3 30
This example uses format to illustrate iterating using do-rows for
side effect:
(do-rows *d2* '(a b) #'(lambda (a b) (format t "~A " (+ a b))))
11 22 33
; No value
map-rows
Where map-columns can be thought of as working through the data
frame column-by-column, map-rows goes through row-by-row. Here we
add the values in each row of two columns:
(map-rows *d2* '(a b) #'+)
#(11 22 33)
Since the length of this vector will always be equal to the data-frame
column length, we can add the results to the data frame as a new
column. Let’s see this in a real-world pattern, subtracting the mean
from a column:
(add-column! *d2* 'c
(map-rows *d2* 'b
#'(lambda (x) (- x (mean (select *d2* t 'b))))))
;; A B C
;; 0 1 10 -10.0
;; 1 2 20 0.0
;; 2 3 30 10.0
You could also have used replace-column! in a similar manner to
replace a column with normalize values.
mask-rows
mask-rows is similar to count-rows, except it returns a bit-vector
for rows matching the predicate. This is useful when you want to pass
the bit vector to another function, like select to retrieve only the
rows matching the predicate.
To view them we’ll need to call the print-data function directly instead
of using the print-object function we installed earlier. Otherwise,
we’ll only see the first 6.
You can refer to any of the column/variable names in the data-frame
directly when constructing the filter predicate. The predicate is
turned into a lambda function, so let, etc is also possible.
Summarising data
Often the first thing you’ll want to do with a data frame is get a
quick summary. You can do that with these functions, and we’ve seen
most of them used in this manual. For more information about these
functions, see the data-frame api reference.
nrow data-frame
return the number of rows in data-frame
ncol data-frame
return the number of columns in data-frame
dims data-frame
return the dimensions of data-frame as a list in (rowscolumns) format
keys data-frame
return a vector of symbols representing column names
column-names data-frame
returns a list of strings of the column names in data-frames
head data-frame &optional n
displays the first n rows of data-frame. n defaults to 6.
tail data-frame &optional n
displays the last n rows of data-frame. n defaults to 6.
describe
describe data-frame
returns the meta-data for the variables in data-frame
describe is a common lisp function that describes an object. In
Lisp-Stat describe prints a description of the data frame and the
three ‘standard’ properties of the variables: type, unit and
description. It is similar to the str command in R. To see an
example use the augmented mtcars data set included in Lisp-Stat. In
this data set, we have added properties describing the variables.
This is a good illustration of why you should always save data frames
in lisp format; properties such as these are lost in CSV format.
(data :mtcars)
LS-USER> (describe mtcars)
MTCARS
Motor Trend Car Road Tests
A data-frame with 32 observations of 12 variables
Variable | Type | Unit | Label
-------- | ---- | ---- | -----------
MODEL | STRING | NIL | NIL
MPG | DOUBLE-FLOAT | M/G | Miles/(US) gallon
CYL | INTEGER | NA | Number of cylinders
DISP | DOUBLE-FLOAT | IN3 | Displacement (cu.in.)
HP | INTEGER | HP | Gross horsepower
DRAT | DOUBLE-FLOAT | NA | Rear axle ratio
WT | DOUBLE-FLOAT | LB | Weight (1000 lbs)
QSEC | DOUBLE-FLOAT | S | 1/4 mile time
VS | BIT | NA | Engine (0=v-shaped, 1=straight)
AM | BIT | NA | Transmission (0=automatic, 1=manual)
GEAR | INTEGER | NA | Number of forward gears
CARB | INTEGER | NA | Number of carburetors
summary
summary data-frame
returns a summary of the variables in data-frame
Summary functions are one of those things that tend to be use-case or application specific. Witness the number of R summary packages; there are at least half a dozen, including hmisc, stat.desc, psych describe, skim and summary tools. In short, there is no one-size-fits-all way to provide summaries, so Lisp-Stat provides the data structures upon which users can customise the summary output. The output you see below is a simple :print-function for each of the summary structure types (numeric, factor, bit and generic).
LS-USER> (summary mtcars)
(
MPG (Miles/(US) gallon)
n: 32
missing: 0
min=10.40
q25=15.40
q50=19.20
mean=20.09
q75=22.80
max=33.90
CYL (Number of cylinders)
14 (44%) x 8, 11 (34%) x 4, 7 (22%) x 6,
DISP (Displacement (cu.in.))
n: 32
missing: 0
min=71.10
q25=120.65
q50=205.87
mean=230.72
q75=334.00
max=472.00
HP (Gross horsepower)
n: 32
missing: 0
min=52
q25=96.00
q50=123
mean=146.69
q75=186.25
max=335
DRAT (Rear axle ratio)
n: 32
missing: 0
min=2.76
q25=3.08
q50=3.70
mean=3.60
q75=3.95
max=4.93
WT (Weight (1000 lbs))
n: 32
missing: 0
min=1.51
q25=2.54
q50=3.33
mean=3.22
q75=3.68
max=5.42
QSEC (1/4 mile time)
n: 32
missing: 0
min=14.50
q25=16.88
q50=17.71
mean=17.85
q75=18.90
max=22.90
VS (Engine (0=v-shaped, 1=straight))
ones: 14 (44%)
AM (Transmission (0=automatic, 1=manual))
ones: 13 (41%)
GEAR (Number of forward gears)
15 (47%) x 3, 12 (38%) x 4, 5 (16%) x 5,
CARB (Number of carburetors)
10 (31%) x 4, 10 (31%) x 2, 7 (22%) x 1, 3 (9%) x 3, 1 (3%) x 6, 1 (3%) x 8, )
Note that the model column, essentially row-name was deleted from
the output. The summary function, designed for human readable
output, removes variables with all unique values, and those with
monotonically increasing numbers (usually row numbers).
To build your own summary function, use the get-summaries function
to get a list of summary structures for the variables in the data
frame, and then print them as you wish.
columns
You can also describe or summarize individual columns:
Data sets often contain missing values and we need to both understand
where and how many are missing, and how to transform or remove them
for downstream operations. In Lisp-Stat, missing values are
represented by the keyword symbol :na. You can control this
encoding during delimited text import by passing an a-list
containing the mapping. By default this is a keyword parameter
map-alist:
(map-alist '(("" . :na)
("NA" . :na)))
The default maps blank cells ("") and ones containing “NA” (not
available) to the keyword :na, which stands for missing.
Some systems encode missing values as numeric, e.g. 99; in this case
you can pass in a map-alist that includes this mapping:
(map-alist '(("" . :na)
("NA" . :na)
(99 . :na)))
We will use the R air-quality dataset to illustrate working with
missing values. Let’s load it now:
(defdf aq
(read-csv rdata:airquality))
Examine
To see missing values we use the predicate missingp. This works on
sequences, arrays and data-frames. It returns a logical sequence,
array or data-frame indicating which values are missing. T
indicates a missing value, NIL means the value is present. Here’s
an example of using missingp on a vector:
and to get a count, use the length function on this vector:
(length *) ; => 37
It’s often convenient to use the summary function to get an overview
of missing values. We can do this because the missingp function is
a transformation of a data-frame that yields another data-frame of
boolean values:
LS-USER> (summary (missingp aq))
X4: 153 (100%) x NIL,
OZONE: 116 (76%) x NIL, 37 (24%) x T,
SOLAR-R: 146 (95%) x NIL, 7 (5%) x T,
WIND: 153 (100%) x NIL,
TEMP: 153 (100%) x NIL,
MONTH: 153 (100%) x NIL,
DAY: 153 (100%) x NIL,
we can see that ozone is missing 37 values, 24% of the total, and
solar-r is missing 7 values.
Exclude
To exclude missing values from a single column, use the Common Lisp
remove function:
To replace missing values we can use the transformation functions.
For example we can recode the missing values in ozone by the mean.
Let’s look at the first six rows of the air quality data-frame:
You can also take random samples from CL sequences and arrays, with or without replacement and in various proportions. For further information see sampling in the select system manual.
Uses Vitter’s Algorithm
D to
efficiently select the rows. Sometimes you may want to use the
algorithm at a lower level. If you don’t want the sample itself, say you
only want the indices, you can directly use map-random-below, which
simply calls a provided function on each index.
This is an enhancement and port to standard common lisp of
ruricolist’s
random-sample.
It also removes the dependency on Trivia, which has a restrictive
license (LLGPL).
Dates & Times
Lisp-Stat uses localtime to
represent dates. This works well, but the system is a bit strict on
input formats, and real-world data can be quite messy at times. For
these cases chronicity
and
cl-date-time-parser
can be helpful. Chronicity returns local-timetimestamp objects,
and is particularly easy to work with.
For example, if you have a variable with dates encoded like: ‘Jan 7
1995’, you can recode the column like we did for the vega movies
data set:
The Distributions system provides a collection of probability distributions and related functions such as:
Sampling from distributions
Moments (e.g mean, variance, skewness, and kurtosis), entropy, and other properties
Probability density/mass functions (pdf) and their logarithm (logpdf)
Moment-generating functions and characteristic functions
Maximum likelihood estimation
Distribution composition and derived distributions
Getting Started
Load the distributions system with (asdf:load-system :distributions) and the plot system with (asdf:load-system :plot/vega). Now generate a sequence of 1000 samples drawn from the standard normal distribution:
It looks like there’s an outlier at 5, but basically you can see it’s centered around 0.
To create a parameterised distribution, pass the parameters when you create the distribution object. In the following example we create a distribution with a mean of 2 and variance of 1 and plot it:
In probability theory and statistics, the gamma distribution is a two-parameter family of continuous probability distributions. The exponential distribution, Erlang distribution, and chi-square distribution are special cases of the gamma distribution. There are two different parameterisations in common use:
With a shape parameter k and a scale parameter θ.
With a shape parameter α = k and an inverse scale parameter β = 1/θ, called a rate parameter.
In each of these forms, both parameters are positive real numbers.
The parameterisation with k and θ appears to be more common in econometrics and certain other applied fields, where for example the gamma distribution is frequently used to model waiting times.
The parameterisation with α and β is more common in Bayesian statistics, where the gamma distribution is used as a conjugate prior distribution for various types of inverse scale (rate) parameters, such as the λ of an exponential distribution or a Poisson distribution.
When the shape parameter has an integer value, the distribution is the Erlang distribution. Since this can be produced by ensuring that the shape parameter has an integer value > 0, the Erlang distribution is not separately implemented.
PDF
The probability density function parameterized by shape-scale is:
$f(x;k,\theta )={\frac {x^{k-1}e^{-x/\theta }}{\theta ^{k}\Gamma (k)}}\quad {\text{ for }}x>0{\text{ and }}k,\theta >0$,
where $\gamma (\alpha ,\beta x)$ is the lower incomplete gamma function.
Usage
Python and Boost use shape & scale for parameterization. Lisp-Stat and R use shape and rate for the default parameterisation. Both forms of parameterization are common. However, since Lisp-Stat’s implementation is based on Boost (because of the restrictive license of R), we perform the conversion $\theta=\frac{1}{\beta}$ internally.
Implementation notes
In the following table k is the shape parameter of the distribution, θ is its scale parameter, x is the random variate, p is the probability and q is (- 1 p). The implementation functions are in the special-functions system.
Function
Implementation
PDF
(/ (gamma-p-derivative k (/ x θ)) θ)
CDF
(incomplete-gamma k (/ x θ))
CDF complement
(upper-incomplete-gamma k (/ x θ))
quantile
(* θ (inverse-incomplete-gamma k p))
quantile complement
(* θ (upper-inverse-incomplete-gamma k p))
mean
kθ
variance
kθ2
mode
(* (1- k) θ), k>1
skewness
(/ 2 (sqrt k))
kurtosis
(+ 3 (/ 6 k))
kurtosis excess
(/ 6 k)
Example
On average, a train arrives at a station once every 15 minutes (θ=15/60). What is the probability there are 10 trains (occurances of the event) within three hours?
As an alternative, we can run a simulation, where we draw from the parameterised distribution and then calculate the percentage of values that fall below our threshold, x = 3:
LLA works with matrices, that is arrays of rank 2, with all numerical values. Categorical variables could be integer coded if you need to.
Setup
lla requires a BLAS and LAPACK shared library. These may be available via
your operating systems package manager, or you can download OpenBLAS, which includes precompiled binaries for MS Windows.
Note
LLA relies on
CFFI
to locate the BLAS & LAPPACK shared libraries. In most cases, this means CFFI
will use the system default search paths. If you encounter errors in
loading the library, consult the CFFI documentation. For MS Windows,
the certain way to successfully load the DLL is to ensure that the
library is on the PATH.
You can also configure the path by setting the cl-user::*lla-configuration* variable like so:
(asdf:load-system :lla)
(use-package 'lla) ;access to the symbols
Getting Started
To make working with matrices easier, we’re going to use the matrix-shorthand library. Load it like so:
(use-package :num-utils.matrix-shorthand)
Matrix Multiplication
mm is the matrix multiplication function. It is generic and can operate on both regular arrays and ‘wrapped’ array types, e.g. hermitian or triangular. In this example we’ll multiple an array by a vector. mx is the short-hand way of defining a matrix, and vec a vector.
An API for taking slices (elements selected by the Cartesian
product of vectors of subscripts for each axis) of array-like
objects. The most important function is select. Unless you want
to define additional methods for select, this is pretty much
all you need from this library. See the API reference for
additional details.
An extensible DSL for selecting a subset of valid
subscripts. This is useful if, for example, you want to resolve
column names in a data frame in your implementation of select.
A set of utility functions for traversing selections in
array-like objects.
It combines the functionality of dplyr’s slice, select and sample methods.
Basic Usage
The most frequently used form is:
(select object selection1 selection2 ...)
where each selection specifies a set of subscripts along the
corresponding axis. The selection specifications are found below.
To select a column, pass in t for the rows selection1, and the
columns names (for a data frame) or column number (for an array) for
selection2. For example, to select the second column of this array
(remember Common Lisp has zero based arrays, so the second column is
at index 1.
and to select a column from the mtcars data frame:
(ql:quickload :data-frame)
(data :mtcars)
(select mtcars t 'mpg)
if you’re selecting from a data frame, you can also use the column
or columns command:
(column mtcars 'mpg)
to select an entire row, pass t for the column selector, and the
row(s) you want for selection1. This example selects the first row
(second row in purely array terms, which are 0 based):
These are called singleton slices. Each singleton slice drops the
dimension: vectors become atoms, matrices become vectors, etc.
Selecting Ranges
(range start end) selects subscripts i where start <= i < end.
When end is nil, the last index is included (cf. subseq). Each
boundary is resolved according to the other rules, if applicable, so
you can use negative integers:
You may sample sequences, arrays and data frames with the sample generic function, and extend it for your own objects. The function signature is:
(defgeneric sample (data n &key
with-replacement
skip-unselected)
By default in common lisp, key values that are not provide are nil, so you need to turn them on if you want them.
:skip-unselected t means to not return the values of the object that were not part of the sample. This is turned off by default because a common use case is splitting a data set into training and test groups, and the second value is ignored by default in Common Lisp. The let-plus package, imported by default in select, makes it easy to destructure into test and training. This example is from the tests included with select:
Note the setting of *random-state*. You should use this pattern of setting *random-state* to a saved seed anytime you need reproducible results (like in a testing scenerio).
The size of the sample is determined by the value of n, which must be between 0 and the number of rows (for an array) or length if a sequence. If (< n 1), then n indicates a proportion of the sample, e.g. 2/3 (values of n less than one may be rational or float. For example, let’s take a training sample of 2/3 of the rows in the mtcars dataset:
Note that n is rounded up when the number of elements is odd and a proportional number is requested.
Extensions
The previous section describes the core functionality. The semantics
can be extended. The extensions in this section are provided by the
library and prove useful in practice. Their implementation provide
good examples of extending the library.
including is convenient if you want the selection to include the
end of the range:
All of these are trivial to implement. If there is something you are
missing, you can easily extend select. Pull request are
welcome.
(ref) is a version of (select) that always returns a single
element, so it can only be used with singleton slices.
Select Semantics
Arguments of select, except the first one, are meant to be
resolved using canonical-representation, in the select-dev
package. If you want to extend select, you should define methods
for canonical-representation. See the source code for the best
examples. Below is a simple example that extends the semantics with
ordinal numbers.
The value returned by canonical-representation needs to be
constructed using canonical-singleton, canonical-range, or
canonical-sequence. You should not use the internal
representation directly as it is subject to change.
You can assume that axis is an integer; this is the
default. An object may define a more complex mapping (such as, for
example, named rows & columns), but unless a method specialized to
that is found, canonical-representation will just query its
dimension (with axis-dimension) and try to find a method
that works on integers.
You need to make sure that the subscript is valid, hence the
assertion.
5.6 - SQLDF
Selecting subsets of data using SQL
Overview
sqldf is a library for querying data in a data-frame using
SQL, optimised for memory consumption. Any query that can be done in
SQL can also be done in the API, but since SQL is widely known, many
developers find it more convenient to use.
To use SQL to query a data frame, the developer uses the sqldf
function, using the data frame name (converted to SQL identifier
format) in place of the table name. sqldf will automatically create
an in-memory SQLite database, copy the contents of the data frame to
it, perform the query, return the results as a new data frame and
delete the database. We have tested this with data frames of 350K
rows and there is no noticeable difference in performance compared to
API based queries.
See the cl-sqlite
documentation for additional functionality provided by the SQLite
library. You can create databases, employ multiple persistent
connections, use prepared statements, etc. with the underlying
library. sqldf is a thin layer for moving data to/from
data-frames.
Basic Usage
sqldf requires the sqlite shared library from the SQLite
project. It may also be available via
your operating systems package manager.
Note
SQLDF relies on
CFFI
to locate the SQLite shared library. In most cases, this means CFFI
will use the system default search paths. If you encounter errors in
loading the library, consult the CFFI documentation. For MS Windows,
the certain way to successfully load the DLL is to ensure that the
library is on the PATH, regardless of whether you install via MSYS
or natively.
To load sqldf:
(asdf:load-system :sqldf)
(use-package 'sqldf) ;access to the symbols
Examples
These examples use the R data sets that are loaded using the example
ls-init
file. If
your init file doesn’t do this, go now and load the example datasets
in the REPL. Mostly these examples are intended to demonstrate
commonly used queries for users who are new to SQL. If you already
know SQL, you can skip this section.
Note
As always when working with lisp-stat,
ensure you are in the LS-USER package
Ordering & Limiting
This example shows how to limit the number of rows output by the
query. It also illustrates changing the column name to meet SQL
identifier requirements. In particular, the R CSV file has
sepal.length for a column name, which is converted to sepal-length
for the data frame, and we query it with sepal_length for SQL
because ‘-’ is not a valid character in SQL identifers.
First, let’s see how big the iris data set is:
LS-USER> iris
#<DATA-FRAME (150 observations of 6 variables)>
X7 is the row name/number from the data set. Since it was not assigned a
column name in the data set, lisp-stat gives it a random name upon
import (X1, X2, X3, …).
Grouping is often useful during the exploratory phase of data
analysis. Here’s how to do it with sqldf:
(pprint
(sqldf "select species, avg(sepal_length) from iris group by species"))
;; SPECIES AVG(SEPAL-LENGTH)
;; 0 setosa 5.0060
;; 1 versicolor 5.9360
;; 2 virginica 6.5880
Nested Select
For each species, show the two rows with the largest sepal lengths:
(pprint
(sqldf "select * from iris i
where x7 in
(select x7 from iris where species = i.species order by sepal_length desc limit 2) order by i.species, i.sepal_length desc"))
;; X7 SEPAL-LENGTH SEPAL-WIDTH PETAL-LENGTH PETAL-WIDTH SPECIES
;; 0 15 5.8 4.0 1.2 0.2 setosa
;; 1 16 5.7 4.4 1.5 0.4 setosa
;; 2 51 7.0 3.2 4.7 1.4 versicolor
;; 3 53 6.9 3.1 4.9 1.5 versicolor
;; 4 132 7.9 3.8 6.4 2.0 virginica
;; 5 118 7.7 3.8 6.7 2.2 virginica
Recall the note above about X7 being the row id. This may be different
depending on how many other data frames with an unnamed column have
been imported in your Lisp-Stat session.
SQLite access
sqldf needs to read and write data frames to the data base, and
these functions are exported for general use.
Write a data frame
create-df-table and write-table can be used to write a data frame
to a database. Each take a connection to a database, which may be file
or memory based, a table name and a data frame. Multiple data frames,
with different table names, may be written to a single SQLite file
this way. For example, to write iris to disk:
LS-USER> (defparameter *conn* (sqlite:connect #P"c:/Users/lisp-stat/data/iris.db3")) ;filel to save to
*CONN*
LS-USER> (sqldf::create-df-table *conn* 'iris iris) ; create the table * schema
NIL
LS-USER> (sqldf:write-table *conn* 'iris iris) ; write the data
NIL
Read a data frame
read-table will read a database table into a data frame and update
the column names to be lisp like by converting “.” and “_” to
“-”. Note that the CSV reading tools of SQLite (for example,
DB-Browser for SQLite are much faster
than the lisp libraries, sometimes 15x faster. This means that often
the quickest way to load a data-frame from CSV data is to first read
it into a SQLite database, and then load the database table into a
data frame. In practice, SQLite also turns out to be a convenient
file format for storing data frames.
Roadmap
SQLDF is currently written using an apparently abandoned library,
cl-sqlite. Pull requests
from 2012 have been made with no response from the author, and the
SQLite C API has improved considerably in the 12 years since
the cl-sqlite FFI was last updated.
We choose CL-SQLite because, at the time of writing, it was the only
SQLite library with a commercially acceptable license. Since then
CLSQL has migrated to a BSD license and
is a better option for new development. Not only does it support
CommonSQL, the
de-facto SQL query syntax for Common Lisp, it also supports several
additional databases.
Version 2 of SQLDF will use CLSQL, possibly including some of the
CSV and other extensions available
in SQLite. Benchmarks show that SQLite’s CSV import is about 15x
faster than cl-csv, and a
FFI wrapper of SQLite’s CSV importer would be a good addition to
Lisp-Stat.
Joins
Joins on tables are not implemented in SQLDF, though there is no
technical reason they could not be. This will be done as part of the
CLSQL conversion and involves more advanced SQL
parsing. SXQL is worth
investigating as a SQL parser.
5.7 - Statistics
Statistical functions
Overview
statistics is a library that consolidates three well-known statistical libraries:
The statistics library from numerical-utilities
Larry Hunter’s cl-statistics
Gary Warren King’s cl-mathstats
There are a few challenges in using these as independent systems on projects though:
There is a good amount of overlap. Everyone implements, for example mean (as does alexandria, cephes, and almost every other library out there).
In the case of mean, variance, etc., the functions deal only with samples, not distributions
This library brings these three systems under a single ‘umbrella’, and adds a few missing ones. To do this we use Tim Bradshaw’s conduit-packages. For the few functions that require dispatch on type (sample data vs. a distribution), we use typecase because of its simplicity and not needing another system. There’s a slight performance hit here in the case of run-time determination of types, but until it’s a problem prefer it. Some alternatives considered for dispatch was https://github.com/pcostanza/filtered-functions.
nu-statistics
These functions cover sample moments in detail, and are accurate. They include up to forth moments, and are well suited to the work of an econometrist (and were written by one).
lh-statistics
These were written by Larry Hunter, based on the methods described in Bernard Rosner’s book, Fundamentals of Biostatistics 5th Edition, along with some from the CLASP system. They cover a wide range of statistical applications. Note that lh-statistics uses lists and not vectors, so you’ll need to convert. To see what’s available see the statistics github repo.
gwk-statistics
These are from Gary Warren King, and also partially based on CLASP. It is well written, and the functions have excellent documentation. The major reason we don’t include it by default is because it uses an older ecosystem of libraries that duplicate more widely used system (for example, numerical utilities, alexandria). If you want to use these, you’ll need to uncomment the appropriate code in the ASDF and pkgdcl.lisp files.
ls-statistics
These are considered the most complete, and they account for various types and dispatch properly.
Accuracy
LH and GWK statistics compute quantiles, CDF, PDF, etc. using routines from CLASP, that in turn are based on algorithms from Numerical Recipes. These are known to be accurate to only about four decimal places. This is probably accurate enough for many statistical problem, however should you need greater accuracy look at the distributions system. The computations there are based on special-functions, which has accuracy around 15 digits. Unfortunately documentation of distributions and the ‘wrapping’ of them here are incomplete, so you’ll need to know the pattern, e.g. pdf-gamma, cdf-gamma, etc., which is described in the link above.
Versions
Because this system is likely to change rapidly, we have adopted a system of versioning proposed in defpackage+. This is also the system alexandria uses where a version number is appended to the API. So, statistics-1 is our current package name. statistics-2 will be the next and so on. If you don’t like these names, you can always change it locally using a package local nickname.
Dictionary
scale
scale scale is generic function whose default method centers and/or scales the columns of a numeric matrix. This is neccessary when the units of measurement for your data differ. The scale function is provided for this purpose.
(defun standard-scale (x &key center scale)
Returns
The function returns three values:
(x - x̄) / s where X̄ is the mean and S is the standard deviation
the center value used
the scale value used
Parameters
CENTRE value to center on. (mean x) by default
SCALE value to scale by. (sd x) by default
If center or scale is nil, do not scale or center respectively.
The library assumes working with 64 bit double-floats. It will
probably work with single-float as well. Whilst we would prefer to
implement the complex domain, the majority of the sources do
not. Tabled below are the special function implementations and their
source. This library has a focus on high accuracy double-float
calculations using the latest algorithms.
function
source
erf
libm
erfc
libm
inverse-erf
Boost
inverse-erfc
Boost
log-gamma
libm
gamma
Cephes
incomplete-gamma
Boost
Error rates
The following table shows the peak and mean errors using Boost test
data. Tests run on MS Windows 10 with SBCL 2.0.10. Boost results taken
from the Boost error function,
inverse
error
function
and
log-gamma
pages.
erf
Data Set
Boost (MS C++)
Special-Functions
erf small values
Max = 0.841ε (Mean = 0.0687ε)
Max = 6.10e-5ε (Mean = 4.58e-7ε)
erf medium values
Max = 1ε (Mean = 0.119ε)
Max = 1ε (Mean = 0.003ε)
erf large values
Max = 0ε (Mean = 0ε)
N/A erf range 0 < x < 6
erfc
Data Set
Boost (MS C++)
Special-Functions
erfc small values
Max = 0ε (Mean = 0)
Max = 1ε (Mean = 0.00667ε)
erfc medium values
Max = 1.65ε (Mean = 0.373ε)
Max = 1.71ε (Mean = 0.182ε)
erfc large values
Max = 1.14ε (Mean = 0.248ε)
Max = 2.31e-15ε (Mean = 8.86e-18ε)
inverse-erf/c
Data Set
Boost (MS C++)
Special-Functions
inverse-erf
Max = 1.09ε (Mean = 0.502ε)
Max = 2ε (Mean = 0.434ε)
inverse-erfc
Max = 1ε (Mean = 0.491ε)
Max = 2ε (Mean = 0.425ε)
log-gamma
Data Set
Boost (MS C++)
Special-Functions
factorials
Max = 0.914ε (Mean = 0.175ε)
Max = 2.10ε (Mean = 0.569ε)
near 0
Max = 0.964ε (Mean = 0.462ε)
Max = 1.93ε (Mean = 0.662ε)
near 1
Max = 0.867ε (Mean = 0.468ε)
Max = 0.50ε (Mean = 0.0183ε)
near 2
Max = 0.591ε (Mean = 0.159ε)
Max = 0.0156ε (Mean = 3.83d-4ε)
near -10
Max = 4.22ε (Mean = 1.33ε)
Max = 4.83d+5ε (Mean = 3.06d+4ε)
near -55
Max = 0.821ε (Mean = 0.419ε)
Max = 8.16d+4ε (Mean = 4.53d+3ε)
The results for log gamma are good near 1 and 2, bettering those of
Boost, however are worse (relatively speaking) at values of x > 8. I
don’t have an explanation for this, since the libm values match Boost
more closely. For example:
libm:lgamma provides an additional 4 digits of accuracy over
spfn:log-gamma when compared to the Boost test answer, despite using
identical computations. log-gamma is still within 12 digits of agreement
though, and likely good enough for most uses.
The lisp specification mentions neither NaN nor infinity, so any proper
treatment of these is going to be either implementation specific or
using a third party library.
We are using the
float-features
library. There is also some support for infinity in the extended-reals
package of
numerical-utilities,
but it is not comprehensive. Openlibm and Cephes have definitions, but
we don’t want to introduce a large dependency just to get these
definitions.
Test data
The test data is based on Boost test data. You can run all the tests
using the ASDF test op:
(asdf:test-system :special-functions)
By default the test summary values (the same as in Boost) are printed
after each test, along with the key epsilon values.
7.3 - Code Repository
Collection of XLisp and Common Lisp statistical routines
Below is a partial list of the consolidated XLispStat packages from
UCLA and CMU repositories. There is a great deal more XLispStat code
available that was not submitted to these archives, and a search for
an algorithm or technique that includes the term “xlispstat” will
often turn up interesting results.
Functions useful for experimentation in Genetic Algorithms. It is
hopefully compatible with Lucid Common Lisp (also known as Sun
Common Lisp). The implementation is a “standard” GA, similar to
Grefenstette’s work. Baker’s SUS selection algorithm is employed, 2
point crossover is maintained at 60%, and mutation is very low.
Selection is based on proportional fitness. This GA uses
generations. It is also important to note that this GA maximizes.
William M. Spears. “Permission is hereby granted to copy all or any
part of this program for free distribution, however this header is
required on all copies.”
Common Lisp files for various standard inductive learning algorithms
that all use the same basic data format and same interface. It also
includes automatic testing software for running learning curves that
compare multiple systems and utilities for plotting and
statistically evaluating the results. Included are:
AQ: Early DNF learner.
Backprop: The standard multi-layer neural-net learning method.
Bayes Indp: Simple naive or “idiot’s” Bayesian classifier.
Cobweb: A probabilistic clustering system.
Foil: A first-order Horn-clause learner (Prolog and Lisp versions).
ID3: Decision tree learner with a number of features.
KNN: K nearest neighbor (instance-based) algorithm.
Perceptron: Early one-layer neural-net algorithm.
PFOIL: Propositional version of FOIL for learning DNF.
PFOIL-CNF: Propositional version of FOIL for learning CNF.
Raymond J. Mooney. “This program may be freely copied, used, or
modified provided that this copyright notice is included in each copy
of this code and parts thereof.”
Common Lisp implementation of “Quickprop”, a variation on
back-propagation. For a description of the Quickprop algorithm, see
Faster-Learning Variations on Back-Propagation: An Empirical
Study
by Scott E. Fahlman in Proceedings of the 1988 Connectionist Models
Summer School, Morgan-Kaufmann, 1988. Scott E. Fahlman. Public
domain.
[README]
Various combinatorial functions for XLispStat. There are other
Common Lisp libraries for this, for example
cl-permutation. It’s
worth searching for something in Quicklisp too. No license
specified.
runge.lsp and integr.lsp are from Gerald Roylance 1982 CLMATH
package. integr.lsp has Simpson’s rule and the trapezoid
rule. runge.lsp integrates runge-kutta differential equations by
various methods.
Roylance code is non-commercial use only. Jan de Leeuw’s code has
no license specified.
This directory contains the code from the Lawson and Hanson book,
Solving Least Squares
Problems,
translated with f2cl, tweaked for Xlisp-Stat by Jan de Leeuw. No
license specified.
This is an f2cl translation, very incomplete, of the NSWC
mathematics library. The FORTRAN, plus a great manual, is available
on github. The report is
NSWCDD/TR-92/425, by Alfred H. Morris, Jr. dated January 1993. No
license specified, but this code is commonly considered public
domain.
Code from Numerical Recipes in FORTRAN, first edition, translated
with Waikato’s f2cl and tweaked for XLisp-Stat by Jan de Leeuw. No
license specified.
Code for annealing, simplex and other optimization problems. Various
licenses. These days, better implementations are available, for
example the
linear-programming
library.
Statistics
Algorithms
AS 190 Probabilities and Upper Quantiles for the Studentized Range.
AS 241 The Percentage Points of the Normal Distribution
AS 243 Cumulative Distribution Function of the Non-Central T Distribution
TOMS 744 A stochastic algorithm for global optimization with constraints
AS algorithms: B. Narasimhan (naras@euler.bd.psu.edu) “You can freely use and
distribute this code provided you don’t remove this notice. NO
WARRANTIES, EXPLICIT or IMPLIED”
TOMS: F. Michael Rabinowitz. No license specified.
Fits Goodman’s RC model to the array X. Also included is a set of
functions for APL like array operations. The four basic APL
operators (see, for example, Garry Helzel, An Encyclopedia of APL,
2e edition, 1989, I-APL, 6611 Linville Drive, Weed., CA) are
inner-product, outer-product, reduce, and scan. They can be used to
produce new binary and unary functions from existing ones.
Unknown author. No license specified.
A function. The argument is a list of lists of strings. Each element
of the list corresponds with a variable, the elements of the list
corresponding with a variable are the labels of that variable, which
are either strings or characters or numbers or symbols. The program
returns a matrix of strings coding all the profiles. Unknown
author. License not specified.
A compilation of probability densities, cumulative distribution
functions, and their inverses (quantile functions), by Jan de
Leeuw. No license specified.
Maximum likelihood estimation of Weibull parameters. M. Ennis. No license specified.
Classroom Statistics
The systems in the
introstat
directory are meant to be used in teaching situations. For the most
part they use XLispStat’s graphical system to introduce students to
statistical concepts. They are generally simple in nature from a the
perspective of a statistical practitioner.
ElToY is a collection of three programs written in
XLISP-STAT. Dist-toy displays a univariate distribution dynamically
linked to its parameters. CLT-toy provides an illustration of the
central limit theorem for univariate distributions. ElToY provides a
mechanism for displaying the prior and posterior distributions for a
conjugate family dynamically linked so that changes to the prior
affect the posterior and visa versa. Russell Almond
almond@stat.washington.edu. GPL v2.
Graphical Display of Analysis of Variance with the Boxplot Matrix.
Extension of the standard one-way box plot to cross-classified data
with multiple observations per cell. Richard M. Heiberger
rmh@astro.ocis.temple.edu No license specified.
[Docs]
Contains methods for regression diagnostics using dynamic graphics,
including all the methods discussed in Cook and Weisberg (1989)
Technometrics, 277-312. Includes documentation written in
LaTeX. sandy@umnstat.stat.umn.edu No license specified.
[Docs}
Flipped Empirical Distribution Function. Parallel-FEDF,
FEDF-ScatterPlot, FEDF-StarPlot written in XLISP-STAT. These plots are
suggested for exploring multidimensional data suggested in “Journal of
Computational and Graphical Statistics”, Vol. 4, No. 4, pp.335-343.
97/07/18. Lee, Kyungmi & Huh, Moon Yul myhuh@yurim.skku.ac.kr No
license specified.
PDF graphics output from XlispStat PDFPlot is a XlispStat class to
generate PDF files from LispStat plot objects. Steven D. Majewski
sdm7g@virginia.edu. No license specified.
RXridge.LSP adds shrinkage regression calculation and graphical
ridge “trace” display functionality to the XLisp-Stat, ver2.1
release 3+ implementation of LISP-STAT. Bob Obenchain. No license
specified.
BAYES-LIN is an extension of the XLISP-STAT object-oriented
statistical computing environment, which adds to XLISP-STAT some
object prototypes appropriate for carrying out local computation via
message-passing between clique-tree nodes of Bayes linear belief
networks. Darren J. Wilkinson. No license specified.
[Docs]
Bayesian Poisson Regression using the Gibbs Sampler Sensitivity
Analysis through Dynamic Graphics. A set of programs that allow you
to do Bayesian sensitivity analysis dynamically for a variety of
models. B. Narasimhan (naras@stat.fsu.edu) License restricted to
non-commercial use only.
[Docs]
A regression analysis usually consists of several stages such as
variable selection, transformation and residual diagnosis.
Inference is often made from the selected model without regard to
the model selection methods that proceeded it. This can result in
overoptimistic and biased inferences. We first characterize data
analytic actions as functions acting on regression models. We
investigate the extent of the problem and test bootstrap, jackknife
and sample splitting methods for ameliorating it. We also
demonstrate an interactive XLISP-STAT system for assessing the cost
of the data analysis while it is taking place. Julian
J. Faraway. BSD license.
[Docs]
A function to estimate coefficients and dispersions in a generalized
linear model with random effects. Guanghan Liu
gliu@math.ucla.edu. No license specified.
Implements Taylor & Hilton’s rules for balanced ANOVA designs and
draws the Hasse diagram of nesting
relationships. Philip Iversen piversen@iastate.edu. License restricted to
non-commercial use only.
Implementation of an algorithm to project on the intersection of r
closed convex sets. Further details and references are in Mathar,
Cyclic Projections in Data Analysis, Operations Research
Proceedings 1988, Springer, 1989. Jan de Leeuw. No license
specified.
Order and Influence in Regression Strategy. The methods (tactics)
of regression data analysis such as variable selection,
transformation and outlier detection are characterised as functions
acting on regression models and returning regression models. The
ordering of the tactics, that is the strategy, is studied. A method
for the generation of acceptable models supported by the choice of
regression data analysis methods is described with a view to
determining if two capable statisticians may reasonably hold
differing views on the same data. Optimal strategies are
considered. The idea of influential points is extended from
estimation to the model building process itself both quantitatively
and qualitatively. The methods described are not intended for the
entirely automatic analysis of data, rather to assist the
statistician in examining regression data at a strategic level.
Julian J. Faraway julian@stat.lsa.umich.edu. BSD license.
A XLispStat tool to investigate order in Regression Strategy
particularly for finding and examining the models found by changing
the ordering of the actions in a regression analysis. Julian Faraway
julian@stat.lsa.umich.edu. License restricted to non-commercial use
only.
XLISP-STAT software to perform Bayesian Predictive Simultaneous
Variable and Transformation Selection for regression. A
criterion-based model selection algorithm. Jennifer A. Hoeting
jah@stat.colostate.edu. License restricted to non-commercial use
only.
Robust
There are three robust systems in the
robust
directory:
This is the Xlisp-Stat version of
ROSEPACK,
the robust regression package developed by Holland, Welsch, and
Klema around 1975. See Holland and Welsch, Commun. Statist. A6,
1977, 813-827. See also the Xlisp-Stat book, pages 173-177, for an
alternative approach. Jan de Leeuw. No license specified.
There is also robust statistical code for
location
and
scale.
Regularized bi-variate splines with smoothing and tension according
to Mitasova and Mitas. Cubic splines according to Green and
Silverman. Jan de Leeuw. No license specified.
The super smoothing algorithm, originally implemented in FORTRAN by
Jerome Friedman of Stanford University, is a method by which a
smooth curve may be fitted to a two-dimensional array of points. Its
implementation is presented here in the XLISP-STAT language. Jason
Bond. No license specified.
[DOCS]
XLispStat code to facilitate interactive bandwidth choice for
estimator (3.14), page 44 in Bagkavos (2003), “BIAS REDUCTION IN
NONPARAMETRIC HAZARD RATE ESTIMATION”. No license specified.
Produces variograms using algorithms from C.V. Deutsch and
A.G. Journel, “GSLIB: Geostatistical Software Library and User’s
Guide, Oxford University Press, New York, 1992. Stanley
S. Bentow. No license specified.
[DOCS]
A set of XLISP-STAT routines for the interactive, dynamic,
exploratory analysis of survival data. E. Neely Atkinson
(neely@odin.mda.uth.tmc.edu) “This software may be freely redistributed.”
[Docs]
Sapaclisp is a collection of Common Lisp functions that can be used to
carry out many of the computations described in the SAPA book:
Donald B. Percival and Andrew T. Walden, “Spectral Analysis for
Physical Applications: Multitaper and Conventional Univariate
Techniques”, Cambridge University Press, Cambridge, England, 1993.
The SAPA book uses a number of time series as examples of various
spectral analysis techniques.
Note
This archive contains SAPA converted to XLispStat. A Common
Lisp version can be
obtained from the CMU archive.
From the description:
Sapaclisp features functions for converting to/from decibels, the
FORTRAN sign function, log of the gamma function, manipulating
polynomials, root finding, simple numerical integration, matrix
functions, Cholesky and modified Gram-Schmidt (i.e., Q-R) matrix
decompositions, sample means and variances, sample medians,
computation of quantiles from various distributions, linear least
squares, discrete Fourier transform, fast Fourier transform, chirp
transform, low-pass filters, high-pass filters, band-pass filters,
sample auto-covariance sequence, auto-regressive spectral estimates,
least squares, forward/backward least squares, Burg’s algorithm, the
Yule-Walker method, periodogram, direct spectral estimates, lag window
spectral estimates, WOSA spectral estimates, sample cepstrum, time
series bandwidth, cumulative periodogram test statistic for white
noise, and Fisher’s g statistic.
License: “Use and copying of this software and preparation of
derivative works based upon this software are permitted. Any
distribution of this software or derivative works must comply with all
applicable United States export control laws.”
XLispStat functions for time series analysis, data editing, data
selection, and other statistical operations. W. Hatch
(bts!bill@uunet.uu.net). Public Domain.
Tests
The tests
directory
contains code to do one-sample and two-sample Kolmogorov-Smirnov test
(with no estimated parameters) and code to do Mann-Whitney and
Wilcoxon rank signed rank tests.
The majority of the files in the utilities
directory
are specific to XLISP-STAT and unlikely to be useful. In most cases
better alternatives now exist for Common Lisp. A few that may be worth
investigating have been noted below.
A series of routines to allow users of Xlisp or LispStat to
interactively transfer data to and access functions in New S. Steve
McKinney kilroy@biostat.washington.edu. License restricted to
non-commercial use only.
A set of XLISP functions that can be used to read ASCII files into
lists of lists, using formatted input. The main function is
read-file, which has as arguments a filename and a FORTRAN type
format string (with f, i, x, t, and a formats) Jan Deleeuw
deleeuw@laplace.sscnet.ucla.edu “THIS SOFTWARE CAN BE FREELY
DISTRIBUTED, USED, AND MODIFIED.”
As the name suggests. Marty Hall
hall@aplcenmp.apl.jhu.edu. “Permission is granted for any use or
modification of this code provided this notice is retained."
[OVERVIEW]
8 - Contribution Guidelines
How to contribute to Lisp-Stat
This section describes the mechanics of how to contribute code to
Lisp-Stat. Legal requirements, community guidelines, code of
conduct, etc. For details on how to contribute code and documentation,
see links on nav sidebar to the left under Contributing.
For ideas about what you might contribute, please see
open issues on github and the ideas page. The
organisation repository contains the
individual sub-projects. Contributions to
documentation are
especially welcome.
Contributor License Agreement
Contributor License Agreements (CLAs) are common and accepted in open
source projects. We all wish for Lisp-Stat to be used and distributed
as widely as possible, and for its users to be confident about the
origins and continuing existence of the code. The CLA help us achieve
that goal. Although common, many in the Lisp community are unaware of
CLAs or their importance.
Some often asked questions include:
Why do you need a CLA?
We need a CLA because, by law, all rights reside with the originator
of a work unless otherwise agreed. The CLA allows the project to
accept and distribute your contributions. Without your consent via a
CLA, the project has no rights to use the code. Here’s what Google has
to say in their CLA policy page:
Standard inbound license
Using one standard inbound license that grants the receiving company broad permission to use contributed code in products is beneficial to the company and downstream users alike.
Technology companies will naturally want to make productive use of any code made available to them. However, if all of the code being received by a company was subject to various inbound licenses with conflicting terms, the process for authorizing the use of the code would be cumbersome because of the need for constant checks for compliance with the various licenses. Whenever contributed code were to be used, the particular license terms for every single file would need to be reviewed to ascertain whether the application would be permitted under the terms of that code’s specific license. This would require considerable human resources and would slow down the engineers trying to utilize the code.
The benefits that a company receives under a standard inbound license pass to downstream users as well. Explicit patent permissions and disclaimers of obligations and warranties clarify the recipients’ rights and duties. The broad grant of rights provides code recipients opportunities to make productive use of the software. Adherence to a single standard license promotes consistency and common understanding for all parties involved.
How do I sign?
In order to be legally binding a certain amount of legal ceremony must
take place. This varies by jurisdiction. As an individual
‘clickwrap’ or ‘browser
wrap’ agreements are used.
For corporations, a ‘wet signature’ is required because it is valid
everywhere and avoids ambiguity of assent.
If you are an individual contributor, making a pull request from a
personal account, the cla-assistant will
automatically prompt you to digitally sign as part of the PR.
What does it do?
The CLA essentially does three things. It ensures that the contributor agrees:
To allow the project to use the source code and redistribute it
The contribution is theirs to give, e.g. does not belong to their employer or someone else
Does not contain any patented ‘stuff’.
Mechanics of the CLA
The Lisp-Stat project uses CLAs to accept regular contributions from
individuals and corporations, and to accept larger grants of existing
software products, for example if you wished to contribute a large
XLISP-STAT library.
Contributions to this project must be accompanied by a Contributor
License Agreement. You (or your employer) retain the copyright to your
contribution; this simply gives us permission to use and redistribute
your contributions as part of the project.
You generally only need to submit a CLA once, so if you have already
submitted one (even if it was for a different project), you do not
need to do it again.
Code of Conduct
The following code of conduct is not meant as a means for punishment,
action or censorship for the mailing list or project. Instead, it is
meant to set the tone, expectations and comfort level for contributors
and those wishing to participate in the community.
We ask everyone to be welcoming, friendly, and patient.
Flame wars and insults are unacceptable in any fashion, by any party.
Anything can be asked, and “RTFM” is not an acceptable answer.
Neither is “it’s in the archives, go read them”.
Statements made by core developers can be quoted outside of the list.
Statements made by others can not be quoted outside the list without explicit permission. - Anonymised paraphrased statements “someone asked about…” are OK - direct quotes with or without names are not appropriate.
The community administrators reserve the right to revoke the subscription of members (including mentors) that persistently fail to abide by this Code of Conduct.
8.1 - Contributing Code
How to contribute code to Lisp-Stat
First, if you are contributing on behalf of your employer, ensure you
have signed a contributor license
agreement. Then
follow these steps for contributing to Lisp-Stat:
First you need the Lisp-Stat source code. The core systems are found
on the Lisp-Stat github page. For the
individual systems, just check out the one you are interested in. For
the entire Lisp-Stat system, at a minimum you will need:
Other dependencies will be pulled in by Quicklisp.
Development occurs on the “master” branch. To get all the repos, you
can use the following command in the directory you want to be your top
level dev space:
Before you start, send a message to the Lisp-Stat mailing
list or file an issue on
Github describing your proposed changes. Doing this helps to verify
that your changes will work with what others are doing and have
planned for the project. Importantly, there may be some existing code
or design work for you to leverage that is not yet published, and we’d
hate to see work duplicated unnecessarily.
Be patient, it may take folks a while to understand your
requirements. For large systems or design changes, a design document
is preferred. For small changes, issues and the mailing list are fine.
Once your suggested changes are agreed, you can modify the source code
and add some features using your favorite IDE.
The following sections provide tips for working on the project:
Coding Convention
Please consider the following before submitting a pull request:
All code should include unit tests. Older projects use fiveam as the test framework for new projects. New project should use Parachute.
Contributions should pass existing unit tests
New unit tests should be provided to demonstrate bugs and fixes
Indentation in Common Lisp is important for readability. Contributions should adhere to these guidelines. For the most part, a properly configured Emacs will do this automatically.
Suggested editor settings for code contributions
No line breaks in (doc)strings, otherwise try to keep it within 80 columns. Remove trailing whitespace. ‘modern’ coding style. Suggested Emacs snippet:
Github includes code review
tools that can be used as
part of a pull request. We recommend using a triangular
workflow and
feature/bug branches in your own repository to work from. Once you
submit a pull request, one of the committers will review it and
possibly request modifications.
As a contributor you should organise
(squash) your
git commits to make them understandable to reviewers:
Combine WIP and other small commits together.
Address multiple issues, for smaller bug fixes or enhancements, with a single commit.
Use separate commits to allow efficient review, separating out formatting changes or simple refactoring from core changes or additions.
Rebase this chain of commits on top of the current master
Once all the comments in the review have been addressed, a Lisp-Stat committer completes the following steps to commit the patch:
If the master branch has moved forward since the review, rebase the branch from the pull request on the latest master and re-run tests.
If all tests pass, the committer amends the last commit message in the series to include “this closes #1234”. This can be done with interactive rebase. When on the branch issue: git rebase -i HEAD^
Change where it says “pick” on the line with the last commit, replacing it with “r” or “reword”. It replays the commit giving you the opportunity the change the commit message.
The committer pushes the commit(s) to the github repo
The committer resolves the issue with a message like "Fixed in <Git commit SHA>".
Additional Info
Where to start?
If you are new to statistics or Lisp, documentation updates are always
a good place to start. You will become familiar with the workflow,
learn how the code functions and generally become better acquainted
with how Lisp-Stat operates. Besides, any contribution will require
documentation updates, so it’s good to learn this system first.
If you are coming from an existing statistical environment, consider
porting a XLispStat package that you find useful to Lisp-Stat. Use
the XLS compatibility layer to
help. If there is a function missing in XLS, raise an issue and we’ll
create it. Some XLispStat code to browse:
Keep in mind that some of these rely on the XLispStat graphics
system, which was native to the platform. LISP-STAT uses Vega for
visualizations, so there isn’t a direct mapping. Non-graphical code
should be a straight forward port.
You could also look at CRAN, which
contains thousands of high-quality packages.
For specific ideas that would help, see the
ideas page.
Issue Guidelines
Please comment on issues in github, making your concerns known. Please
also vote for issues that are a high priority for you.
Please refrain from editing descriptions and comments if possible, as
edits spam the mailing list and clutter the audit trails, which is
otherwise very useful. Instead, preview descriptions and comments
using the preview button (on the right) before posting them. Keep
descriptions brief and save more elaborate proposals for comments,
since descriptions are included in GitHub automatically sent
messages. If you change your mind, note this in a new comment, rather
than editing an older comment. The issue should preserve this history
of the discussion.
8.2 - Contributing to Documentation
You can help make Lisp-Stat documentation better
Creating and updating documentation is a great way to learn. You will
not only become more familiar with Common Lisp, you have a chance to
investigate the internals of all parts of a statistical system.
We use Hugo to format and generate the website,
the Docsy theme for styling and
site structure, and Netlify to manage the
deployment of the documentation site (what you are reading now). Hugo
is an open-source static site generator that provides us with
templates, content organisation in a standard directory structure, and
a website generation engine. You write the pages in Markdown (or HTML
if you want), and Hugo wraps them up into a website.
All submissions, including submissions by project members, require review. We
use GitHub pull requests for this purpose. Consult
GitHub Help for more
information on using pull requests.
Repository Organisation
Declt generates documentation for individual systems in Markdown
format. These are kept with the project, e.g. select/docs/select.md.
Here’s a quick guide to updating the docs. It assumes you are familiar
with the GitHub workflow and you are happy to use the automated preview
of your doc updates:
If you are not yet ready for a review, add “WIP” to the PR name to indicate
it’s a work in progress. (Don’t add the Hugo property
“draft = true” to the page front matter, because that prevents the
auto-deployment of the content preview described in the next point.)
Wait for the automated PR workflow to do some checks. When it’s ready,
you should see a comment like this: deploy/netlify — Deploy preview ready!
Click Details to the right of “Deploy preview ready” to see a preview
of your updates.
Continue updating your doc and pushing your changes until you’re happy with
the content.
When you’re ready for a review, add a comment to the PR, and remove any
“WIP” markers.
Updating a single page
If you’ve just spotted something you’d like to change while using the
docs, Docsy has a shortcut for you (do not use this for reference
docs):
Click Edit this page in the top right hand corner of the page.
If you don’t already have an up to date fork of the project repo, you are prompted to get one - click Fork this repository and propose changes or Update your Fork to get an up to date version of the project to edit. The appropriate page in your fork is displayed in edit mode.
Follow the rest of the Quick Start process above to make, preview, and propose your changes.
Previewing locally
If you want to run your own local Hugo server to preview your changes as you work:
Follow the instructions in Getting started to install Hugo and any other tools you need. You’ll need at least Hugo version 0.45 (we recommend using the most recent available version), and it must be the extended version, which supports SCSS.
Fork the Lisp-Stat documentation repo into your own repository project, then create a local copy using git clone. Don’t forget to use --recurse-submodules or you won’t pull down some of the code you need to generate a working site.
Run hugo server in the site root directory. By default your site will be available at http://localhost:1313/. Now that you’re serving your site locally, Hugo will watch for changes to the content and automatically refresh your site.
Continue with the usual GitHub workflow to edit files, commit them, push the
changes up to your fork, and create a pull request.
Creating an issue
If you’ve found a problem in the docs, but are not sure how to fix it
yourself, please create an issue in the Lisp-Stat documentation
repo. You can
also create an issue about a specific page by clicking the Create
Issue button in the top right hand corner of the page.
The functions underlying the statistical distributions require skills
in numerical programming. If you like being ‘close to the metal’, this
is a good area for contributions. Suitable for medium-advanced level
programmers. In particular we need implementations of:
gamma
incomplete gamma (upper & lower)
inverse incomplete gamma
This work is partially complete and makes a good starting point for
someone who wants to make a substantial contribution.
Documentation
Better and more documentation is always welcome, and a great way to
learn. Suitable for beginners to Common Lisp or statistics.
Jupyter-Lab Integrations
Jupyter Lab has two nice integrations with Pandas, the Python version
of Data-Frame, that would make great contributions:
Qgrid, which allows editing a
data frame in Jupyter Lab, and Jupyter
DataTables. There are
many more Pandas/Jupyter integrations, and any of them would be
welcome additions to the Lisp-Stat ecosystem.
Plotting
LISP-STAT has a basic plotting system, but there is always room for
improvement. An interactive REPL based plotting system should be
possible with a medium amount of
effort. Remote-js provides a
working example of running JavaScript in a browser from a REPL, and
could combined with something like Electron and a DSL for Vega-lite
specifications. This may be a 4-6 week project for someone with
JavaScript and HTML skills. There are other Plotly/Vega options, so
if this interests you, open an issue and we can discuss. I have
working examples of much of this, but all fragmented examples. Skills:
good web/JavaScript, beginner lisp.
Regression
We have some code for ‘quick & dirty’ regressions and need a more
robust DSL (Domain Specific Language). As a prototype, the -proto
regression objects from XLISP-STAT would be both useful and be a good
experiment to see what the final form should take. This is a
relatively straightforward port, e.g. defproto -> defclass and
defmeth -> defmethod. Skill level: medium in both Lisp and
statistics, or willing to learn.
Vector Mathematics
We have code for vectorized versions of all Common Lisp functions,
living in the elmt package. It now only works on vectors. Shadowing
Common Lisp mathematical operators is possible, and more natural. This
task is to make elmt vectorized math functions work on lists as well
as vectors, and to implement shadowing of Common Lisp. This task
requires at least medium-high level Lisp skills, since you will be
working with both packages and shadowing. We also need to run the
ANSI Common Lisp conformance tests on the results to ensure nothing
gets broken in the process.
Continuous Integration
If you have experience with Github’s CI tools, a CI setup for
Lisp-Stat would be a great help. This allows people making pull
requests to immediately know if their patches break anything. Beginner
level Lisp.